



Key takeaways:
Typical continuous deployment pipelines require significant effort and complex combination of IaC tools to manage and track the changes of targeting environments. GitOps together with Operator is introduced, it can enable the convenience of deploying and shipping the software to a production environment.
What is DevOps?
- DevOps unifies Dev and Ops teams, encouraging collaboration and shared responsibility for a more efficient software development process through streamlined communication across the entire lifecycle.
- DevOps represents a shift in culture that hinges on establishing trust between development and operations teams. The objective is to minimize silos by promoting collaborative work practices that enable the teams to function in unison. By facilitating shared ownership and open communication, DevOps ensures a more cohesive and efficient software development lifecycle.
- Common DevOps practices include automation, iterative software development, rapid software delivery and automated infrastructure deployment.
What is GitOps?
- “GitOps is an operating model pattern for cloud native applications and Kubernetes storing application and declarative infrastructure code in Git as source of truth used for automated continuous delivery.”
- GitOps defines software state declaratively in a repository that maintains a complete history of changes for version control, auditing, and visibility over deployments and environments. Software agents retrieve and monitor the desired state from the repository, ensuring system alignment with intended configuration for streamlined software management and efficient, reliable delivery.
- If it can be described it can be automated with GitOps such as: apps, config, dashboard, monitoring, infrastructure …
How is GitOps approach different from DevOps approach?
DevOps often use a “Push” approach for deployments using CD pipelines while, for GitOps a “Pull” approach is often used.
- With a “Push” approach, you are typically pushing out the code to the environment, so you need to know where the environment is, what you are pushing out there. And you need to know a lot more.
- With a “Pull” approach, Kubernetes uses an Operator running inside the cluster to monitor our Git repository to find what’s needed and what’s described there, and then it will make the deployment happen.
In DevOps the app and deployment pipelines are often separated with infrastructure as code scripts being used kind of in a one-time approach to deploy the environment in a static manner.
- It’s like you write the code for infrastructure and deploy it but it is often not maintained. You don’t have that continuous sync between your environment and where your code lives to make sure your environment doesn’t drift. And if you do need to make updates, you are making updates to the code and then pushing it out in a manual manner. Even if it is in a continuous deployment manner, the live environment does not always match the code, we can run into issues there
GitOps together with with an Operator that handles Operations tasks such as create, change, delete in Kubernetes cluster based on what’s described in Git.
What are challenges of Kubernetes DevOps pipeline?
A standard Kubernetes DevOps pipeline involves the following steps:
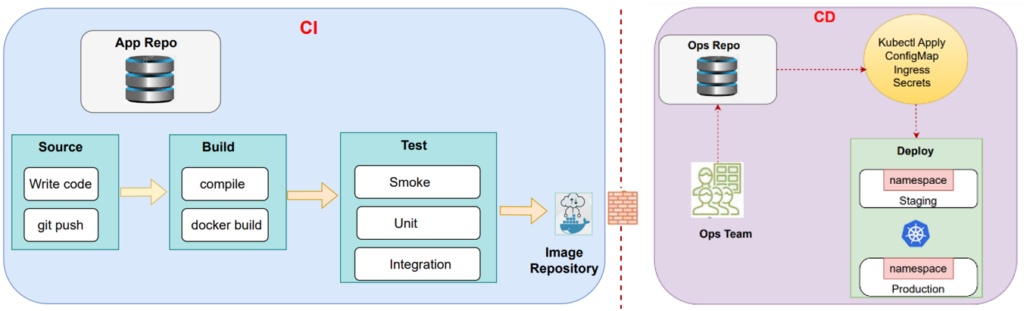
- Step 1: Code commit – a developer makes a code commit to a repository, the committed code may include a Dockerfile that specifies the container image, as well as a manifest file that defines either a deployment object or a Helm chart.
- Step 2: Build – a CI tool processes the Dockerfile to create a new version of the container image.
- Step 3: Testing – Smoke, unit, and integration test.
- Step 4: Generate artifacts – CI tool pushes the container image to an image repository, and it’s handed over to the Ops team.
- Step 5: Deploy – Ops team is deploying that code into a repo that they have.
- We have two different repos (App repo and Ops repo), and we are starting to see where things become disconnected.
- Ops team has a release pipeline to deploy code from the repo to the Kubernetes cluster or even they might even just store the scripts there and then manually deploy from the infrastructure as code scripts to the Kubernetes cluster.
What challenges does this pipeline create?
While this pipeline is effective when running smoothly, addressing issues can be challenging. Any individual with access to the cluster can manipulate or delete pods through kubectl commands, whether intentionally or unintentionally. Additionally, there may be unintended environmental effects resulting from other active processes, incidents, or deployments. Conventional DevOps pipelines do not provide a simple means for developers to restore a cluster to its previous stable state.
After identifying an issue, developers have the option to re-run the CD step. However, some alterations, such as deleting pods or modifying the number of replicas, may cause disruptions to applications that are currently running. It may be challenging to detect these problems in some scenarios, while in others, the issues may be visible but the process of resolving them can be complex and time-consuming. Even after resolving an issue, determining whether the current state of the environment aligns with the desired state can be quite challenging.
How GitOps help?
To address the problem of managing the CD step, GitOps can be used. While the automated CI steps typically remain the same, a GitOps tool, such as Argo CD, runs within the cluster and monitors the manifest files in the code repository. This helps ensure that the cluster stays synchronized with the repository, thereby simplifying the CD process.
By using GitOps, a tool is employed to periodically synchronize the active clusters with the intended target state found in the code repository, typically on GitHub. This method offers a security boost to the cluster by dividing the authorizations for CI and CD activities.
A GitOps pipeline employs a tool such as Argo CD that routinely compares the current state of the cluster in Kubernetes to the intended state specified in the manifest files. When changes are made to the cluster or pods are deployed outside the CI/CD process, the tool detects the deviations and can automatically revert the cluster to its desired state. With Git as the solitary source of truth, it guarantees that the applications are consistently synchronized.
Kubernetes GitOps pipeline
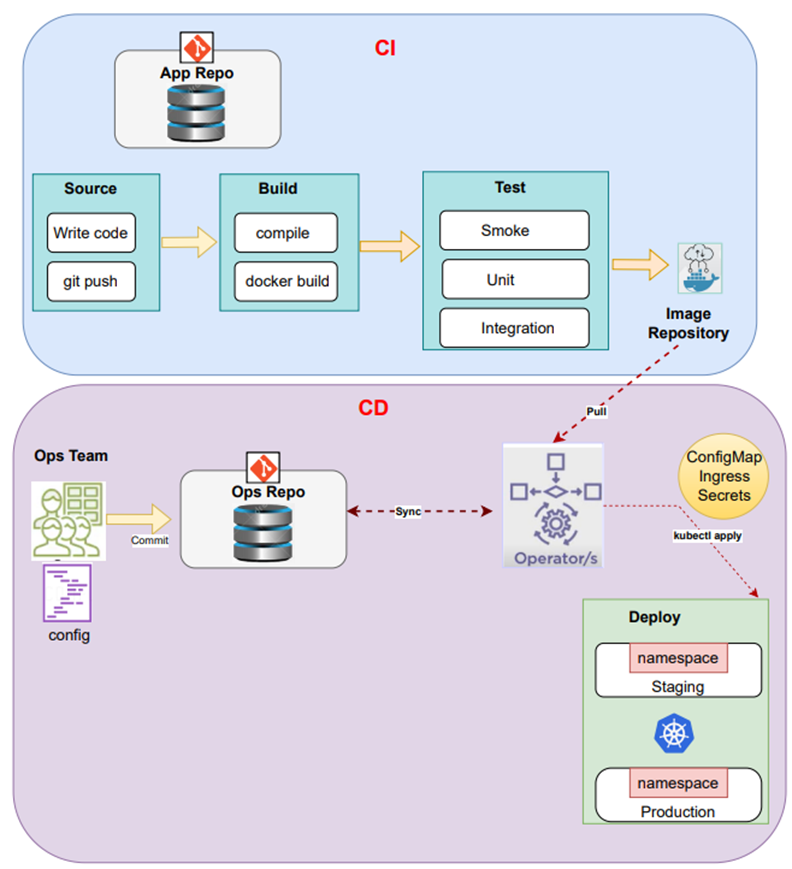
The CI process is exactly the same with DevOps Pipeline. From the deployment onwards, things work differently.
- Step 1: Code commit – Operator creates the configuration code, so this is your infrastructure-as-code scripts, commit that into Ops repository.
- Step 2: Syncing– Having a sync between Ops repository and your actual Kubernetes cluster by using an Operator. The Operator is running in your Kubernetes cluster, and it has permissions to go ahead and perform the actions that you need to perform like your kubectl apply, or create, whatever you choose, and it will create the API objects that are needed. So, your config map, your services, your deployments, your actual pods, it will create all things.
- Step 3: Pull and Deploy – Operator will pull the container, so the app code from the container registry or if it’s Helm chart, it will pull that down, and deploy it to Kubernetes.
- An Operator has the capability to watch a container register. That way, if the Dev team makes changes to the app code, and they push it up to the container registry, the Operator will see it, pull it down, and deploy it to the Kubernetes environment. And if there are changes in configuration, it will pull those changes down as well.