



Introduction
In the realm of advanced AI, a Large Language Model (LLM) stands out as a multifaceted tool capable of responding to queries, generating text, providing data-driven answers, creating images, performing translations, and beyond. Unveiling the true potential of this technology involves delving into the intricacies of its operations like fine-tuning and optimizing computational processes, and leveraging high-end computing resources.
Efficiency Benchmark
When evaluating the effectiveness of an application, it is essential to examine both its accuracy and the speed of its response. Even if the application demonstrates high precision, its failure to meet communication standards can diminish its overall effectiveness. Emphasizing the importance of not only achieving correct results but also seamlessly adhering to established communication protocols is crucial. This approach ensures the delivery of a comprehensive and valuable solution.
Now, let’s delve into the efficiency aspect of Large Language Models. These models, constructed on vast textual data, boast a profound knowledge base. Consequently, when deploying them, traversing the entire network to generate a response becomes evident.
Memory Usage in LLM Operations:
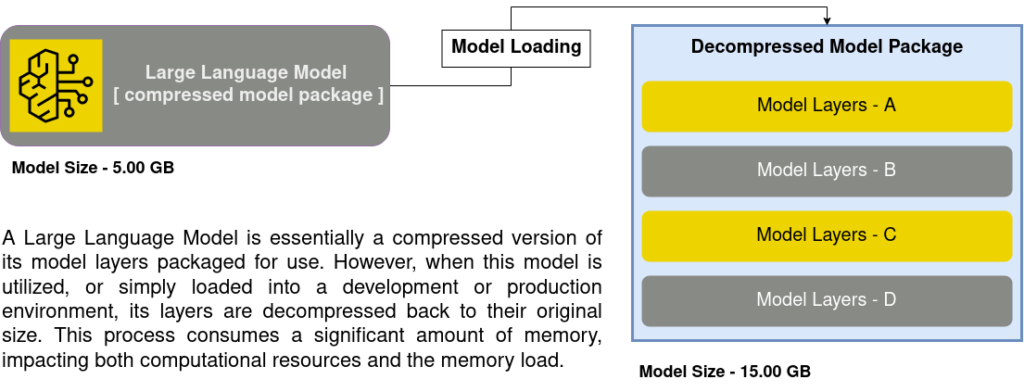
We previously explored in the provided image the memory consumption associated with loading a large language model. However, this is not the extent of the matter. When it comes to tasks such as fine-tuning or serving the model for predictions, it not only consumes the memory required for loading but surpasses the space occupied by the model initially.
First and foremost, it’s important to check how big the model is. For example, think about a model with 3 billion parameters and another with 7 billion. Clearly, the second one is twice as big as the first, meaning it uses twice as much memory. Now, let’s look at fine-tuning the model and see how it works on different devices like CPU and GPU.
Fine-Tuning using CPU
CPUs are versatile processors capable of handling a wide range of calculations. They can dedicate significant power to multitasking, allowing them to process multiple sets of linear instructions simultaneously for faster execution.
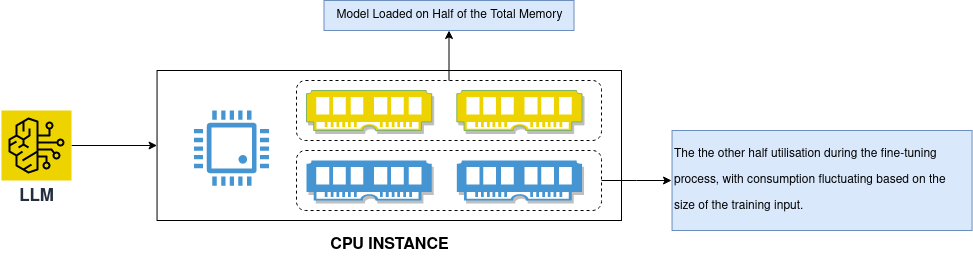
From the image above, we assume our llm model uses half of the memory for loading and the remaining half for subsequent fine-tuning. However, the adequacy for successful fine-tuning and the possibility of surpassing these needs depends on the model’s size and the training dataset. Larger datasets result in increased memory consumption.
Although opting for a higher-memory instance and multi-core CPUs may slightly expedite our fine-tuning process, accomplishing the entire procedure within an optimal timeframe remains a challenge. This is due to the limited efficiency of CPUs in supporting a diverse set of parallel tasks essential for hastening the deep neural network process. Despite the potential increase in CPU instance utilization, the outcome may not exhibit significant efficiency.
To address this challenge, the GPU comes into play. In the following discussion, we will explore how to harness the power of the GPU to optimize the efficiency of LLM operations.
Fine-Tuning using GPU
GPUs excel in managing specialized computations, equipped with thousands of cores capable of concurrently executing operations on numerous data points. By batching instructions and processing extensive amounts of data at high speeds, they can accelerate workloads beyond what a CPU can achieve. We also have multiple options for leveraging GPU power as below.
Model Parallelism (Efficient Resource Utilisation)
In machine learning, diverse approaches to parallelism serve several purposes:
First, we’ll take a look at how the model parallelism is actually executed using multiple GPU’s from the below image.
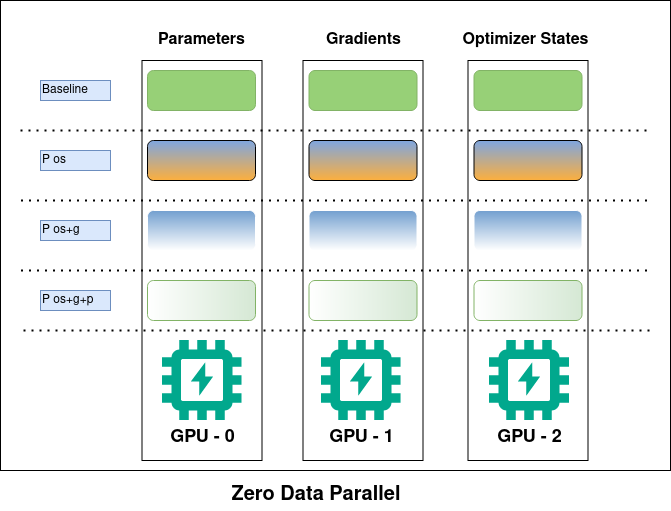
First, let’s explore the concept of Zero Data Parallelism. In this approach, each GPU actively loads specific segments of the model parameters, gradients, and optimizer states. When the runtime requires the complete layer parameters, the GPUs actively synchronize to exchange the missing parts, ensuring that each GPU actively possesses the comprehensive information necessary for smooth operation.
To illustrate, let’s consider a scenario where we aim to load a 50 GB model using multiple GPUs, but each GPU has a capacity of only 24 GB. It practically becomes impossible to load the entire model onto a single GPU. This is where the mentioned techniques come into play—by actively distributing the model across each GPU and actively bringing the segments together whenever they are utilized.
However, what if we possess an even larger model, and the available resources are insufficient to facilitate the entire operation, such as fine-tuning? In fine-tuning, where we impart the desired behavior to the language model based on our training data without constructing it from the ground up, we can opt to load only a subset of layers instead of the entire model. To accomplish this, we can utilize the Quantization method.
Quantization (Reducing Memory Consumption)
Quantization techniques help save memory and processing power by using simpler data formats, like 8-bit integers (int8), to represent weights and activations. This allows you to use bigger models that wouldn’t normally fit in memory and makes calculations faster.
While loading the model we can use the following configuration to load the model in 8-bit:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
)
model = AutoModelForCausalLM.from_pretrained(
your_model_name,
quantization_config=bnb_config,
device_map=”auto”,
)
model.config.use_cache = False
Once we have loaded the model in 8-bit, we will implement Parameter Efficient Fine Tuning (PEFT)
Peft (Parameter Efficient Fine Tuning)
PEFT (Parameter Efficient Fine Tuning) operates as its name suggests. Since the Language Model (LLM) is built on the transformer architecture, an increase in the model’s capability leads to a corresponding increase in its size, becoming larger and larger. In this scenario, PEFT proves beneficial by focusing on fine-tuning only the smaller parameters of the model while keeping the majority of the parameters from the pre-trained LLMs frozen. In simpler terms, we are training only a subset of layers in the model, rather than training the entire model, aligning it with our specific use case.
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=”Represents the alpha value, a method adjusting learning rates per layer during training.“,
lora_dropout=”Likely the dropout rate, a neural network regularization technique.“,
r=”The rank of the update matrices, expressed in int.“,
bias=”Specifies if the bias parameters should be trained. Can be 'none', 'all' or 'lora_only'“,
task_type=”Task model is being trained for, Like: ‘CAUSAL_LM’“,
target_modules=[“The modules (for example, attention blocks) to apply the LoRA update matrices“],
)
Upon finalizing our configurations, these parameter values are fed into the trainer, with the selection of the trainer contingent on our specific choice. In this instance, we are demonstrating the procedure using the SFT Trainer (Supervise Fine-Tuning Trainer).
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
peft_config=peft_config,
"And other training parameters so on"
)
trainer.train()
Now we understand how to efficiently utilize resources during LLM operations, and we can effectively implement strategies on both fronts—deploying large models and reducing resource costs.
Conclusion
Therefore, in the pursuit of refining LLM performance across diverse applications, leveraging high-end computing resources, particularly GPUs, proves essential. The strategic use of GPU power, along with techniques like model parallelism and quantization, not only addresses memory constraints but also contributes to the overall efficiency of LLM operations. This comprehensive approach enables the deployment of large models and the reduction of resource costs, ultimately enhancing the effectiveness of Large Language Models.