


From Basics to Battle-Tested Implementation
Reading time: 8 minutes | Series: Part 3 of 9
In Part 2, we saw how single-threaded consumption creates rebalancing death spirals. The solution is the Thread Pool with Blocking Queue pattern—the most important pattern in this series and the one you’ll use in 80% of real-world scenarios.
This post covers everything: the core architecture, basic implementation, and critical features for reliability (backpressure, rebalancing, graceful shutdown). By the end, you’ll have robust, deployable code.
Architecture: The Two-Layer Design
The thread pool pattern separates consumption from processing through a clean two-layer architecture:
Layer 1: Consumer Thread (The Fast Poller)
- Continuously polls Kafka for new messages
- Never blocks on processing logic
- Manages backpressure by pausing/resuming partitions
- Handles rebalancing and offset commits
Layer 2: Worker Thread Pool (The Processors)
- Pull messages from a blocking queue
- Execute business logic (database queries, API calls, etc.)
- Scale horizontally by adding more workers
The Bridge: Blocking Queue
- Decouples the two layers
- Provides natural backpressure through bounded capacity
- Thread-safe coordination point
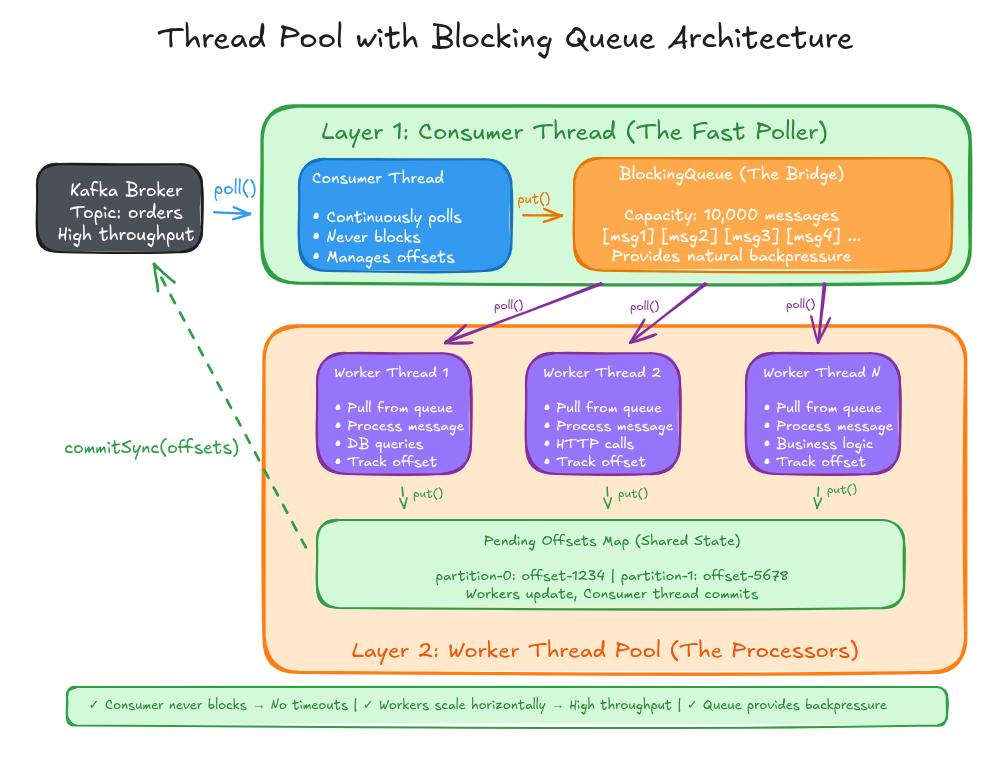
This solves the fundamental problem: the consumer thread never waits for processing, so it always polls Kafka on time, eliminating rebalancing risks.
Implementation with Reliability Features
Here’s the implementation with all essential features:
java
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.*;
public class ThreadPoolConsumer {
private final KafkaConsumer<String, String> consumer;
private final ExecutorService workerPool;
private final BlockingQueue<ConsumerRecord<String, String>> messageQueue;
private final Map<TopicPartition, OffsetAndMetadata> pendingOffsets;
private final int queueCapacity;
private volatile boolean running = true;
public ThreadPoolConsumer(String bootstrapServers, String groupId,
String topic, int numWorkers, int queueCapacity) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 300000);
this.consumer = new KafkaConsumer<>(props);
this.queueCapacity = queueCapacity;
this.workerPool = Executors.newFixedThreadPool(numWorkers);
this.messageQueue = new LinkedBlockingQueue<>(queueCapacity);
this.pendingOffsets = new ConcurrentHashMap<>();
// Register rebalance listener
consumer.subscribe(Collections.singletonList(topic), new RebalanceListener());
}
public void start() {
// Start worker threads
for (int i = 0; i < ((ThreadPoolExecutor)workerPool).getCorePoolSize(); i++) {
workerPool.submit(this::workerLoop);
}
consumerLoop();
}
/**
* Consumer loop with backpressure handling
*/
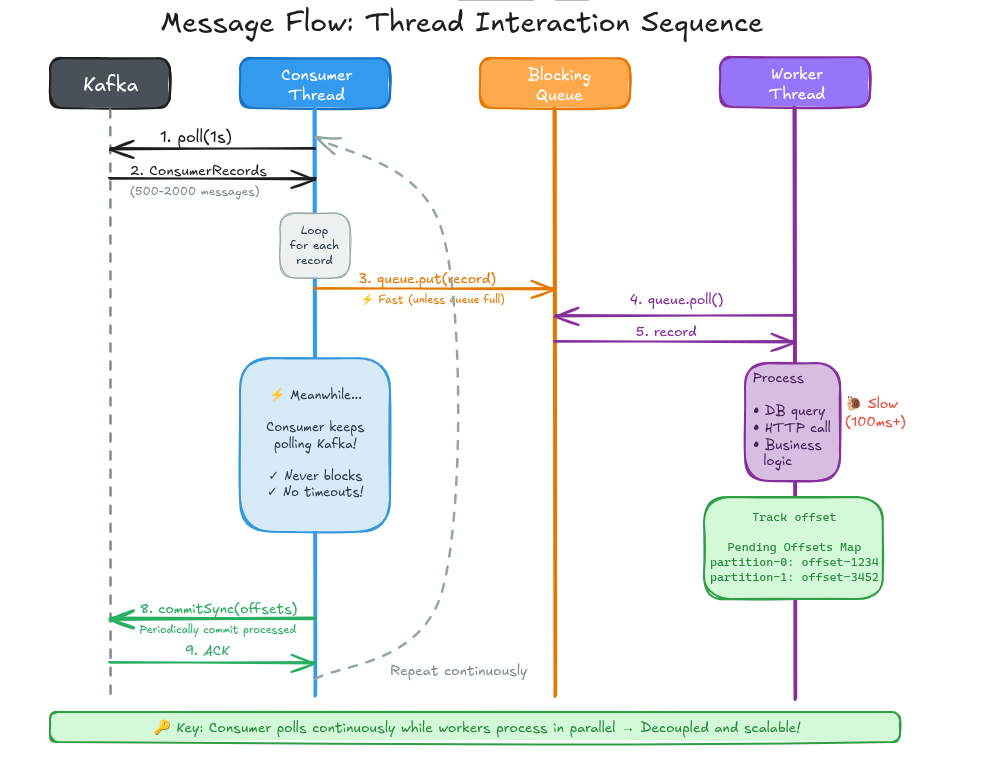
private void consumerLoop() {
try {
while (running) {
// Backpressure: Pause partitions if queue is filling up
handleBackpressure();
// Poll Kafka (always fast, never blocked by processing)
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
// Non-blocking offer with timeout to handle race conditions
try {
if (!messageQueue.offer(record, 100, TimeUnit.MILLISECONDS)) {
// Queue is full - this indicates backpressure isn't catching up
System.err.println("Warning: Queue full despite backpressure, " +
"consider tuning thresholds. Offset: " + record.offset());
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return;
}
}
// Commit offsets asynchronously
commitProcessedOffsets();
}
} finally {
shutdown();
}
}
/**
* Backpressure management: Pause when queue fills, resume when it drains
*/
private void handleBackpressure() {
int queueSize = messageQueue.size();
Set<TopicPartition> assignment = consumer.assignment();
if (queueSize > queueCapacity * 0.8) {
// Queue is 80% full - pause all partitions
consumer.pause(assignment);
System.out.println("Backpressure: Paused partitions (queue: " + queueSize + ")");
} else if (queueSize < queueCapacity * 0.5) {
// Queue is below 50% - resume if paused
Set<TopicPartition> paused = consumer.paused();
if (!paused.isEmpty()) {
consumer.resume(paused);
System.out.println("Backpressure: Resumed partitions (queue: " + queueSize + ")");
}
}
}
/**
* Worker thread: Pull messages from queue and process
*/
private void workerLoop() {
while (running) {
try {
ConsumerRecord<String, String> record =
messageQueue.poll(1, TimeUnit.SECONDS);
if (record != null) {
try {
processMessage(record);
// Track offset for commit only after successful processing
TopicPartition partition =
new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offset =
new OffsetAndMetadata(record.offset() + 1);
synchronized (pendingOffsets) {
pendingOffsets.put(partition, offset);
}
} catch (Exception e) {
// Handle processing failure - log and continue
// In real scenarios, consider DLQ or retry logic
System.err.println("Failed to process record at offset " +
record.offset() + ": " + e.getMessage());
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return;
}
}
}
private void processMessage(ConsumerRecord<String, String> record) {
try {
// Your business logic here
Thread.sleep(100); // Simulate processing
System.out.println("Processed: " + record.value());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
/**
* Async offset commit with callback
*/
private void commitProcessedOffsets() {
synchronized (pendingOffsets) {
if (!pendingOffsets.isEmpty()) {
Map<TopicPartition, OffsetAndMetadata> offsetsToCommit =
new HashMap<>(pendingOffsets);
consumer.commitAsync(offsetsToCommit, (offsets, exception) -> {
if (exception != null) {
System.err.println("Commit failed: " + exception.getMessage());
}
});
pendingOffsets.clear();
}
}
}
/**
* Rebalance listener to handle partition assignment changes
*/
private class RebalanceListener implements ConsumerRebalanceListener {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("Partitions revoked: " + partitions);
// Commit any pending offsets before losing partitions
synchronized (pendingOffsets) {
if (!pendingOffsets.isEmpty()) {
try {
consumer.commitSync(pendingOffsets);
pendingOffsets.clear();
} catch (Exception e) {
System.err.println("Failed to commit on rebalance: " + e);
}
}
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("Partitions assigned: " + partitions);
}
}
/**
* Graceful shutdown: Stop polling, drain queue, commit final offsets
*/
public void shutdown() {
running = false;
// Wait for workers to drain queue
workerPool.shutdown();
try {
System.out.println("Draining queue (size: " + messageQueue.size() + ")...");
workerPool.awaitTermination(30, TimeUnit.SECONDS);
} catch (InterruptedException e) {
workerPool.shutdownNow();
}
// Final commit
synchronized (pendingOffsets) {
if (!pendingOffsets.isEmpty()) {
try {
consumer.commitSync(pendingOffsets);
} catch (Exception e) {
System.err.println("Final commit failed: " + e);
}
}
}
consumer.close();
System.out.println("Shutdown complete");
}
}
Key Features Explained
1. Backpressure with Pause/Resume
The critical fix: when the queue reaches 80% capacity, we pause partitions using consumer.pause(assignment). This tells Kafka to stop delivering data to those partitions, but the consumer keeps polling to maintain its heartbeat. When the queue drains to 50%, we resume.
Why this works:
- ✅ Consumer never blocks for extended periods
- ✅ No
max.poll.interval.msviolations - ✅ Automatic flow control prevents OOM
- ✅ System self-regulates under load
2. Rebalance Handling
The ConsumerRebalanceListener handles partition reassignment during rebalancing:
onPartitionsRevoked(): Called before partitions are taken away. We commit any pending offsets synchronously to avoid losing progress.
onPartitionsAssigned(): Called when new partitions are assigned. We can initialize any partition-specific state here.
Without this listener, uncommitted offsets would be lost during rebalancing, causing duplicate processing.
3. Async Offset Commits
We use commitAsync() instead of commitSync() for better performance:
java
consumer.commitAsync(offsetsToCommit, (offsets, exception) -> {
if (exception != null) {
System.err.println("Commit failed: " + exception.getMessage());
}
});Async commits don’t block the consumer thread, allowing higher throughput. The callback handles failures (though we accept some risk of duplicate processing on restart).
Important: We use commitSync() in critical moments (rebalancing, shutdown) where we can’t afford to lose offsets.
4. Graceful Shutdown
The shutdown sequence ensures no data loss:
- Set
running = false(stops polling loop) - Shutdown worker pool but wait for queue to drain
- Commit any remaining offsets synchronously
- Close consumer
This guarantees all in-flight messages are processed and offsets are committed before exit.
Performance: The Proof
Test Scenario: 100ms processing time per message, Kafka delivers 2,000 messages per poll
| Pattern | Throughput | Processing Time | Consumer State | Risk |
|---|---|---|---|---|
| Single-Threaded | 10 msg/sec | 200 seconds/batch | Blocked | High timeout risk |
| Thread Pool (10 workers) | 100 msg/sec | 20 seconds (parallel) | Responsive | None |
| Thread Pool (50 workers) | 500 msg/sec | 4 seconds (parallel) | Responsive | None |

The thread pool pattern scales linearly with worker count while keeping the consumer responsive. With pause/resume, it handles any load safely.
Key Takeaways
✅ Decouple consumption from processing – Consumer thread stays fast, workers handle slow operations
✅ Pause/resume for backpressure – Prevents OOM and timeout violations when queue fills
✅ Rebalance listener – Commits offsets before partition reassignment to avoid data loss
✅ Async commits – Better performance for routine commits, sync for critical moments
✅ Graceful shutdown – Drains queue and commits final offsets cleanly
✅ Battle-tested – This pattern handles billions of messages daily across the industry
This is your go-to pattern for most Kafka consumption scenarios. It’s robust, scalable, and handles all the edge cases that trip up naive implementations.
References
Diagrams and illustrations created using Claude AI
What’s Next?
In Part 4, we’ll explore the Async CompletableFuture Pattern—a modern approach for I/O-bound processing that uses non-blocking async chains instead of worker threads. It’s more efficient for scenarios dominated by network calls and database queries.
📚 Series Navigation
- Part 1: Foundation
- Part 2: Single-Threaded Anti-Pattern
- Part 3: Thread Pool Pattern (Complete) ← You are here
- Part 4: Async CompletableFuture Pattern
- Part 5-9: [Additional patterns and topics]
Discussion: How many worker threads do you run? Have you encountered queue capacity issues? What’s your backpressure strategy? Share below!