



Word Embedding and Word2Vec have emerged as powerful techniques for understanding and representing the relationships between words. In this article, we will embark on a journey of exploration and implementation, diving into the world of Word Embedding and Word2Vec. By delving into their fundamentals and practical applications, we will uncover how these techniques revolutionize language processing. Join us as we unravel the mysteries of Word Embedding and Word2Vec and learn how to implement them effectively. Let’s unlock the potential of these techniques and enhance our understanding of language in the digital era.
What is Word Embedding?
Enhancing Language with Contextual Transformations Language is dynamic, constantly evolving, and subject to change. Word emending is the process of transforming words by altering or replacing specific letters or segments to improve the overall meaning or convey a different context. It is a powerful technique that showcases the flexibility and complexity of language.
- Origins and Significance of Word Emending: Word emending draws inspiration from various linguistic phenomena such as contractions, abbreviations, and derivations. These transformations not only shape our everyday language but also form the basis of creative writing, poetry, and wordplay. Word emending plays a crucial role in preserving the richness and diversity of language.
- Examples and Applications of Word Emending: a. Portmanteau: Combining two words to create a new word with blended meanings, as seen in “brunch” (breakfast + lunch) or “spork” (spoon + fork). b. Back-formation: Creating a new word by removing a perceived affix, such as “edit” derived from “editor.” c. Diminutive: Altering a word to convey a smaller or more affectionate form, as in “kitty” from “cat.”
- The Role of Word Emending in Natural Language Processing: In the realm of natural language processing, word emending plays a vital role in tasks such as text classification, sentiment analysis, and named entity recognition. By understanding and leveraging the intricacies of word emending, AI models can achieve greater accuracy and contextual understanding.
What is Word2Vec?
Word2Vec is a technique rooted in machine learning that represents words as vectors in a high-dimensional space. By capturing the semantic relationships between words, Word2Vec enables machines to understand the meaning and context of language, leading to advancements in language-related tasks. The basic idea of Word2Vec is to represent each word as a multidimensional vector, and the position of the vector in this high-dimensional space captures the meaning of the word.
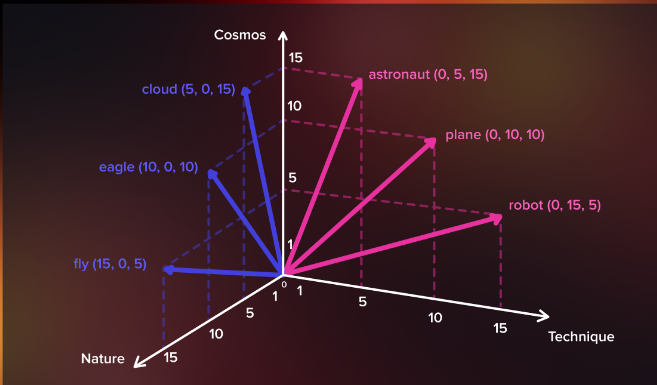
Two variants of Word2Vec
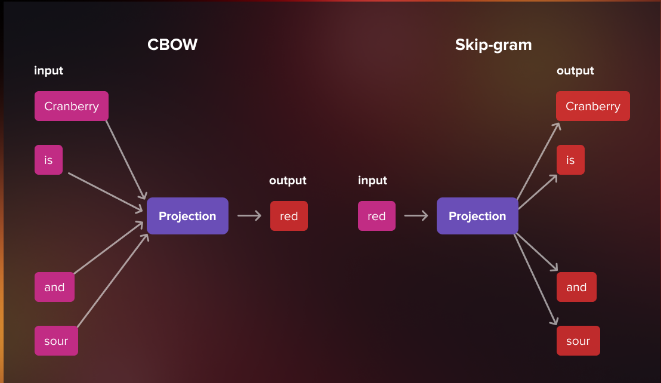
CBOW (Continuous Bag-of-Words)
Understanding CBOW: CBOW is a Word2Vec variant that focuses on predicting a target word based on its surrounding context words. Unlike other models that analyze sequential word order, CBOW treats words as a “bag” of unordered context, making it efficient for training large corpora.
The Architecture of CBOW: CBOW employs a feed-forward neural network architecture with three layers: an input layer, a hidden layer, and an output layer. The input layer represents the context words encoded as one-hot vectors, while the output layer predicts the target word. The hidden layer serves as a bridge, capturing the semantic relationships between the input and output layers.
Training CBOW: During training, CBOW optimizes the model’s weights by minimizing the loss between the predicted target word and the actual target word. By learning the vector representations of words in the hidden layer, CBOW can capture the context-based similarities between words.
Advantages and Applications of CBOW:
a. Efficiency: CBOW is computationally efficient, as it predicts the target word using the sum or average of the context word vectors, rather than considering the entire context.
b. Contextual Understanding: CBOW excels in capturing the meaning and context of words within their surrounding textual environment, making it useful for tasks such as language modeling and document classification.
c. Rare Words: CBOW performs better than Skip-Gram when dealing with rare words, as it combines information from multiple context words to predict the target word.
Skip-Gram
Understanding Skip-Gram: Unlike CBOW, Skip-Gram is a Word2Vec variant that aims to predict the context words given a target word. It emphasizes learning from each target-context pair, providing a fine-grained representation of the relationships between words.
The Architecture of Skip-Gram: Similar to CBOW, Skip-Gram employs a neural network architecture but with reversed roles. The input layer now represents the target word, while the output layer predicts the context words. The hidden layer still captures the semantic relationships between the input and output layers.
Training Skip-Gram: During training, Skip-Gram optimizes the model’s weights by predicting the context words from the target word. By iterating over a large corpus, the model learns to generate accurate representations of words, positioning similar words closer in the vector space.
Advantages and Applications of Skip-Gram:
a. Contextual Flexibility: Skip-Gram excels in understanding the nuances of language, as it learns to predict the diverse context words associated with a target word. This flexibility makes Skip-Gram useful for tasks such as word analogy detection and semantic similarity calculation.
b. Infrequent Words: Skip-Gram performs better than CBOW in handling infrequent words, as it focuses on individual target-context pairs, allowing it to capture the specific context information associated with rare words.
Why is Mastering Word Embedding and Word2Vec Game Changing
Word2Vec is game-changing due to its ability to transform language into dense, context-aware vector representations. This technique allows machines to capture the semantic relationships between words, enabling them to understand language at a deeper level. By representing words as vectors, Word2Vec unlocks the potential for various applications such as sentiment analysis, document clustering, machine translation, and more. It revolutionizes natural language processing by providing a foundation for tasks that require language comprehension and semantic analysis, leading to enhanced accuracy, efficiency, and advancements in AI-driven language-related applications.
Implementation
Here we will be looking a simple implementation using Python Jupyter Notebook
Link to the Dataset: http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Cell_Phones_and_Accessories_5.json.gz
import gensim
import pandas as pd
# The dataset we are using here is a subset of Amazon reviews from the Cell Phones & Accessories category. The data is stored as a JSON file and can be read using pandas.
df = pd.read_json("Cell_Phones_and_Accessories_5.json", lines=True)
# Simple Preprocessing & Tokenization
# The first thing to do for any data science task is to clean the data. For NLP, we apply various processing like converting all the words to lower case, trimming spaces, removing punctuations. This is something we will do over here too.
#
# Additionally, we can also remove stop words like 'and', 'or', 'is', 'the', 'a', 'an' and convert words to their root forms like 'running' to 'run'.
review_text = df.reviewText.apply(gensim.utils.simple_preprocess)
# Training the Word2Vec Model
model = gensim.models.Word2Vec(
window=10,
min_count=2,
workers=4,
)
model.build_vocab(review_text, progress_per=1000)
model.train(review_text, total_examples=model.corpus_count, epochs=model.epochs)
model.save("./word2vec-amazon-cell-accessories-reviews-short.model")
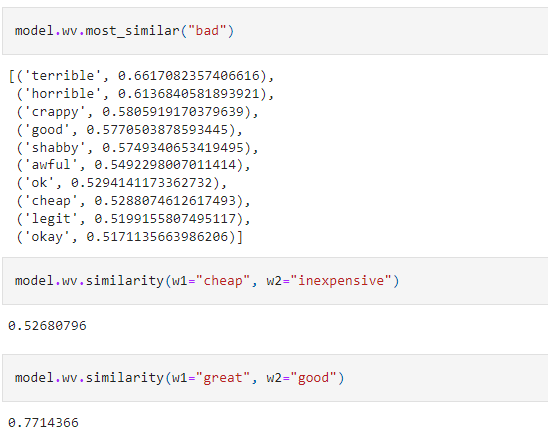
# Finding Similar Words and Similarity between words
model.wv.most_similar("bad")
model.wv.similarity(w1="cheap", w2="inexpensive")
model.wv.similarity(w1="great", w2="good")
Results
Applications of Word Embedding and Word2Vec
- Sentiment Analysis: Word2Vec helps in understanding sentiment by associating positive or negative sentiment words with specific vector directions. This aids sentiment analysis tasks such as determining the sentiment of reviews or social media posts.
- Document Clustering: Word2Vec’s vector representations enable clustering of documents based on their semantic similarities. This facilitates efficient information retrieval, topic modeling, and organizing large text corpora.
- Named Entity Recognition: Word2Vec can enhance named entity recognition systems by capturing the context and semantics of words, improving the accuracy of identifying and classifying named entities in text.
- Machine Translation: Word2Vec improves machine translation systems by aligning words across languages based on their semantic similarities. This assists in capturing word meanings and reducing translation errors.
- Recommendation Systems: Word2Vec can be used to understand user preferences and recommend relevant products, articles, or movies by capturing the semantic relationships between items and user behavior.
Conclusion
Word Embedding and Word2Vec exemplify the power of language in the digital age. Word emending showcases the creative possibilities of linguistic transformations, while Word2Vec enables machines to comprehend language at a deeper level, unlocking new capabilities in natural language processing. As language continues to evolve, understanding and harnessing these techniques will pave the way for future advancements in AI, opening doors to enhanced communication, knowledge discovery, and information retrieval.