



Nowadays, applying AI (Artificiant Intelligence) is probably the most trending approach in software development. Unlocking AI capabilities requires a quite different skill-set and mind-set of software engineers, as well as test engineers.
In this blog, we’ll discover the possible risks during creating a test strategy for AI-based systems. In this context, ‘test strategy’ is the test approaches applied to a specific project.
An AI based system will typically include both AI and non-AI components.
Let’s say for a machine learning system – the most popular AI technology nowadays – we can imagine these components might be machine learning models and supporting data pipelines along with conventional software to integrate them, perhaps providing a link to a database and providing the user interface for the overall system.
The test approach(es) is based on risk analysis for the system, and this risk analysis will also include suggested mitigations or treatments activities. These testing activities will appear as part of the test approach and can be generic testing that can be used for the testing of any software, for example ‘exploratory testing’. Or it can be more specialized testing that specifically addresses those factors associated with AI components and AI based systems such as ‘adversarial attacks’.
Following are a list of typical risks and corresponding potential mitigations that are specific to the testing of machine learning systems. There are possibly many more risks specific to machine learning systems that require mitigation through testing, which are not presented on the following section.
Quality of training data lower than the expectation
Typical data quality issues we identified were reduced accuracy, a biased model and a compromised model.
For instance, with an AI-based system for detecting the swan in images, the traning dataset may includes the swan images in many position such as a flying swan, a swimming swan etc… but the AI-based system may incorrectly classifies a black swan as ‘not a swan’ when the system is used in Australia, the only place in the world where black swan available.
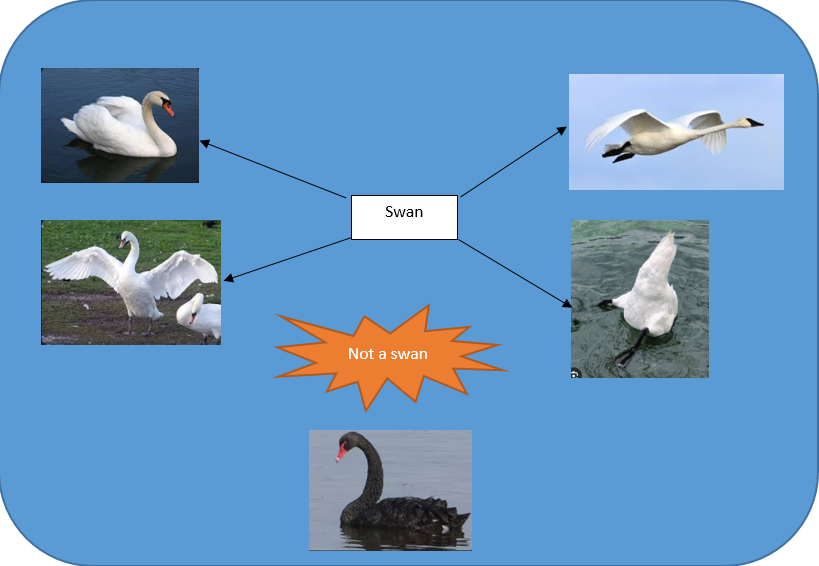
Common mitigations for such issues include the use of reviews, exploratory data analysis and dynamic testing.
The operational data pipeline faulty
Data pipelines collect and deliver the information that will be used in an AI-based component, let’s say for a machine learning model. This is regarding what data to process, how the data will be processed, and where the data to go next.
In other words, a data pipeline is a combination of tools that are used to extract, transform, and load data from one or more sources into a target system. There are three main stages of this flow: data sourcing, data processing, and data delivery. Here’s a breakdown of how it all works:
| Data Sourcing -> | Data Processing -> | Data Delivery |
| Data Warehouse | Transformation | Next Pipeline |
| Cloud storage | Labeling | Data Warehouse |
| Streaming data | Filtering | Data Lake |
| On-premises server | Cleanup | Analytics Connector |
An example of operational data faulty is for an autonomous driving system where the operational data, in this case is the image of a pedestrian may have a flaw in some pixels. This causes the machine learning model to incorrectly classifies to be a non-obstacle object and tells the car to keep the same speed.
This risk can be partly mitigated by the dynamic testing of the individual pipeline components. And once we have confidence in the individual components, we could then perform integration testing of the complete integrated pipeline.
The machine learning workflow used to develop the model may not be optimal
Following is a high-level Machine Learning workflow
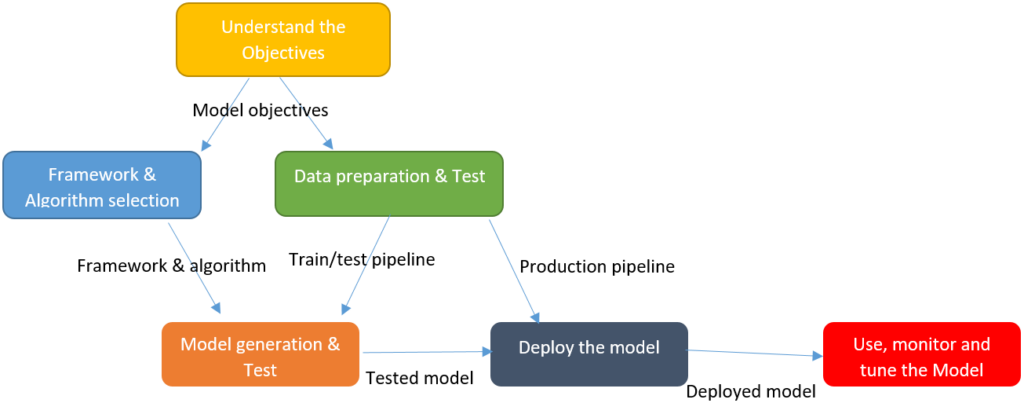
This risk could be due to one or more of the following.
A lack of upfront agreement between the various stakeholders on the make up of the machine learning workflow to be followed.
A poor choice of workflow from the start, or it could be that the developers or data engineers failed to follow the agreed workflow and implemented something different.
Reviews with experts may mitigate the chance of choosing the wrong workflow, while both more hands on management and audits could address the problem that the selected workflow was being poorly implemented.
A poor choice of machine learning, development framework algorithm or any of the settings for these would be likely to result in a suboptimal model.
This risk could be due to a lack of expertise on the part of the decision makers who choose these or due to poor implementation of the evaluation and tuning steps of the machine learning workflow.
Reviews with experts may mitigate the chance of making the wrong development decisions, and better management may ensure that the evaluation, tuning and testing steps of the workflow are followed correctly.
End-users are unhappy with the delivered results from the machine learning model
End-users are unhappy with the delivered results from the machine learning model, even though the desired functional performance criteria were met
In AI and more specifically, machine learning world, the term ‘functional performance’ means how accurate the AI component makes the predictions compared to the actual. This is measured by methods such as Confusion Matrix.
There are mainly two causes for this risk. The first possible cause may be due to the selection of the wrong performance criteria, such as requiring high recall when high precision was needed. An example regarding precision and recall metrics is a spam detection classifier classified eight e-mails in total 15 e-mails as ‘spam’. Five of eight prediction are actually spam e-mails. Hence the precision of this ML model is 5/8, and the recall is 5/12.
For the mitigation of wrong performance criteria, reviews with experts may mitigate the chance of choosing the wrong functional performance metrics. Moreover, experience based testing, such as exploratory testing, could identify that inappropriate criteria have been implemented for the expected use of the model.
The second cause is concept drift. The term ‘Concept drift’ refers to the changes in the operational environment (live or ‘production’ environment) which make the ML model ‘drifts’ out of the original intention. For example, with a spam detection ML model, overtime the spam e-mails patterns may change and the ML model no longer be able to effectively detects the spam.
In which case more frequent testing of the operational system to identify when concept drift occurs might mitigate this risk.
End-users are unhappy with the service provided by a self-learning system
This risk is again associated with unhappy users, this time specifically with the self learning system.
For example, the system may be failing due to the system learning new functionality that is unacceptable, such as Microsoft encountered with their Tay chat bot. This is a chat bot created by Microsoft back in 2016. It was designed to interact with people on Twitter. Unfortunately, the bot has learned some inappropriate behaviours from real Twitter users and started posting some provocative content such as political or gender-sensitive materials.
This risk could potentially be mitigated by the use of automated regression tests that are run after every system update. These tests can ensure that functional performance has not been degraded by changes to the system, or the system may be learning in a way that is not expected by the users, which causes it to behave oddly as far as the users are concerned.
Users are frustrated by not understanding how the AI-based system made its decision
This risk is concerned with explainability interpretability or transparency. It is the risk that users are frustrated because they do not understand how the system comes up with its decisions.
To mitigate this risk, the test strategy should include the testing for Explainability interpretability and transparency. This testing includes perturbing inputs and exploratory testing for explainability, using surveys and questionnaires for both Explainability and interpretability and carrying out documentation reviews for transparency testing.
The model provides excellent predictions when the operational data is similar to the training data, but that it provides poor results if it’s not
This risk is due to overfitting. Let’s say we have three students, A, B, and C, who are preparing for an exam. A has studied only chapters three of the material and left everything else. B is better and memorize the entire material. And the third student, C, has studied and practiced all the material and have a good understanding. Hence, when it comes to the exam, A will only be able to solve the questions if the exam has questions related to chapter 3. Student B will only be able to solve questions if they appear exactly the same as given in the material. Student C will be able to solve all the exam questions in a proper way.
The same happens with machine learning; if the algorithm learns from a small part of the data, it is unable to capture the required data points and hence under fitted. Just like student A.
Suppose the model learns the training dataset, like the B student. They perform very well on the seen dataset but perform badly on unseen data or unknown instances. In such cases, the model is said to be Overfitting.
And if the model performs well with the training dataset and also with the test/unseen dataset, similar to student C, it is said to be a good fit.
To detect the issue of over-fitting, we will have two data set: the trainning set is about 80% of the total dataset. After the training process with includes many iterations, we will test it with the validation set, which is about 20% of the total dataset.
If the machine learning model shows 85% accuracy with training data and 50% accuracy with the test dataset, it means the model is not performing well. In the following chart, the ‘sweet spot’ indicates the ‘good fit’ point of which the model will have a balance between prediction of data from training set v.s. validation set.
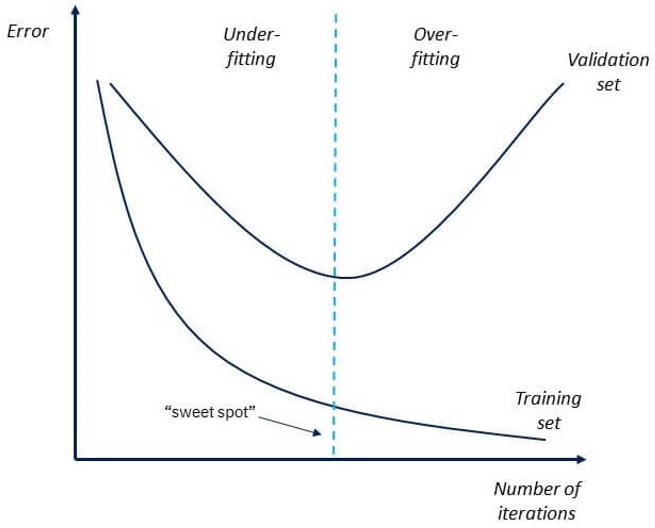
To prevent the Overfitting problem, there are many possible way such as Early Stopping, Train with more data, Feature Selection, Cross-Validation, Data Augmentation, Regularization. Details of these solution are out of scope of this article.
In conclusion
Producing an effective test strategy for AI-based system requires the tester to have a solid understanding regarding the AI technology selected, for instance Machine Learning. Moreover, tester will have to work closely with the SMEs (Subject Matter Experts) in the business domain of the system-under-test. Hopefully, the information included in this blog will play as a general guidance for tester who are getting familiar with AI-based test strategy.
More reading:
Automate Visual Testing with AI – NashTech Insights (nashtechglobal.com)
ReportPortal-AI Report for automation Test – NashTech Insights (nashtechglobal.com)