



GraphQL has become a powerful query language, allowing clients to request what they need without extra data. However, as applications grow more complex, it becomes essential to have scalable solutions. It is where GraphQL federation comes in, providing a structured approach to scaling GraphQL adoptions across multiple services.
To begin with GraphQL Federation, a basic understanding of GraphQL as a query language is essential. Familiarity with schema stitching, although not required, can also be beneficial. The key is to start small and expand the federated architecture as the team’s comfort and the application’s demands grow.
What is GraphQL?

GraphQL is a powerful and flexible query language designed specifically for APIs. It allows clients to request the data they need, making it highly efficient and reducing the amount of data transferred over the network.
Additionally, GraphQL serves as a runtime for executing these queries by interacting with your existing data sources. That means it can work seamlessly with your current databases, services, and APIs, providing a unified and consistent way to access and manipulate data. With GraphQL, developers can define the structure of the responses they want, ensuring that the API evolves without breaking existing queries.
GraphQL also supports real-time updates through subscriptions, allowing clients to receive data changes as they happen. That makes it an excellent choice for applications that require live updates, such as chat apps, dashboards, and collaborative tools.
How Does GraphQL Differ from REST?
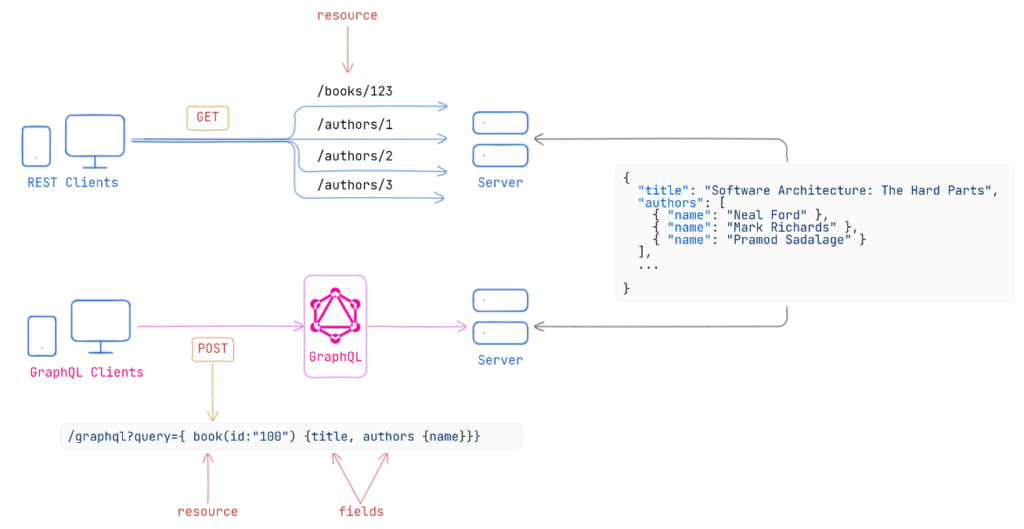
GraphQL and REST are both popular approaches for designing APIs, but they have some key differences:
Data Fetching
- REST: Uses multiple endpoints to fetch different sets of data. Each endpoint corresponds to a specific resource.
- GraphQL: Uses a single endpoint to fetch all the required data. Clients can specify exactly what data they need in a single query.
Flexibility
- REST: Responses are predefined by the server, which can lead to over-fetching or under-fetching of data.
- GraphQL: Clients can request exactly the data they need, which reduces the chances of over-fetching or under-fetching.
Performance
- REST: This can be less efficient because multiple requests might be needed to gather related data from different endpoints.
- GraphQL: More efficient as it allows clients to retrieve all necessary data in a single request.
Versioning
- REST: Often requires versioning of APIs as changes are made to the endpoints.
- GraphQL: Avoids versioning by allowing clients to request only the fields needed, even as the schema evolves.
Error Handling
- REST: Uses HTTP status codes to indicate errors.
- GraphQL: Returns errors in the response body, providing more detailed information about what went wrong.
Learning Curve
- REST: Generally considered easier to learn and implement, especially for those familiar with HTTP and web development.
- GraphQL: Has a steeper learning curve due to its more complex query language and schema definition.
The main difference lies in how they handle data fetching. GraphQL’s single endpoint and query language allow for more precise data retrieval, while REST’s multiple endpoints follow a more structured resource-based approach. Both have their use cases and choosing between them depends on the specific needs of the application.
Scaling GraphQL Adoptions
While a monolithic GraphQL server is simpler and easier to manage, it lacks the scalability and flexibility of schema stitching and federation. Schema stitching offers a way to merge schemas manually, providing a transitional step towards a more decentralized architecture. Federation, on the other hand, is designed for large-scale applications with a focus on service independence and a more structured approach to combining schemas. It allows for a more robust and scalable architecture but comes with increased complexity and a learning curve.
Monolithic GraphQL Architecture
Monolithic GraphQL architecture, characterized by a single, unified codebase, have been the traditional approach to building applications. However, as applications grow in complexity and scale, this architecture often becomes cumbersome to manage. The tightly coupled nature of components in a monolithic system can lead to challenges in scalability, flexibility, and speed of development.
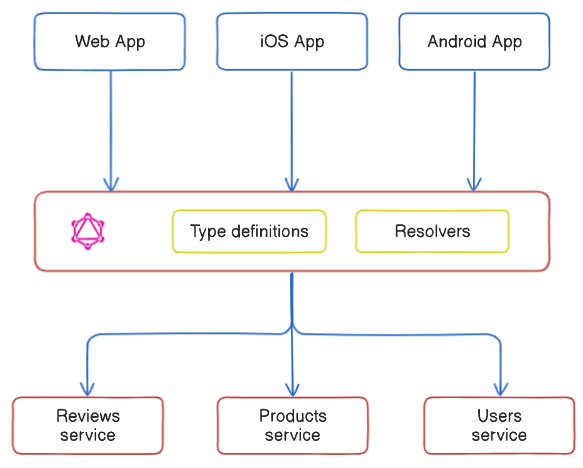
- Centralization: A single GraphQL server handles all the business logic and data fetching.
- Simplicity: Easier to set up and manage due to its centralized nature.
- Single Point of Failure: Can become a bottleneck and impact performance as complexity grows.
- Limited Scalability: Difficult to scale horizontally as the application grows.
Schema Stitching
Schema stitching is a method for combining various GraphQL schemas into a single, unified schema. It allows you to merge schemas from disparate sources, such as APIs or databases, into a unified GraphQL schema that users can query.
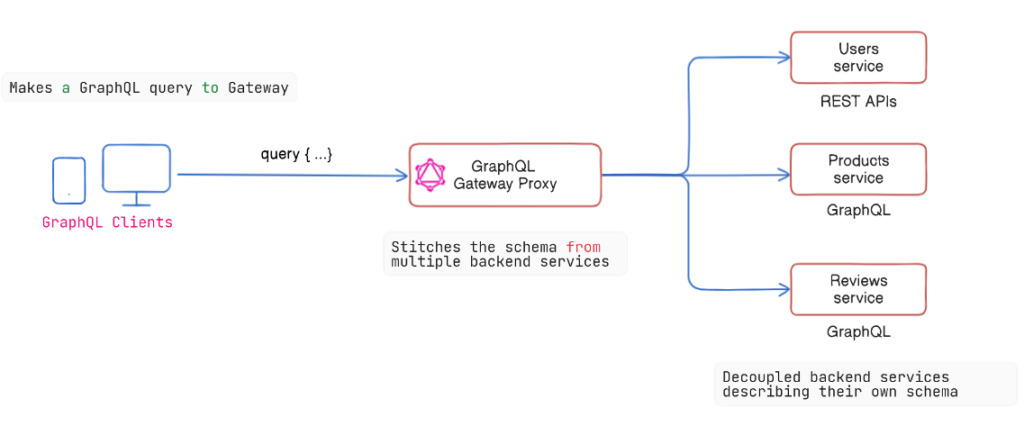
- Combination of Schemas: Merges multiple GraphQL schemas from different services into one.
- Gateway Layer: Acts as an intermediary that stitches together schemas from microservices.
- Flexibility: Allows adding new fields or functionality to an existing schema.
- Manual Effort: Requires explicit knowledge of the underlying schemas to resolve conflicts.
Given that we can manage shared types in schema stitching and resolve fields via the Gateway, it is likely that gateway code can quickly get messy if numerous teams are managing a large number of microservices with many common types. Stitching might not be the most optimal choice for building very large-scale systems. If you have many microservices that use shared types and different microservices are responsible for different fields of a shared type, then it’s probably better to take a look at GraphQL Federation.
What is GraphQL Federation?
GraphQL Federation is a design architecture that allows multiple GraphQL services to work together, forming a single cohesive data graph. This architecture enables a gateway to combine various services into one unified API endpoint. It’s particularly beneficial for organizations with large-scale systems or applications that are decoupled as microservices.
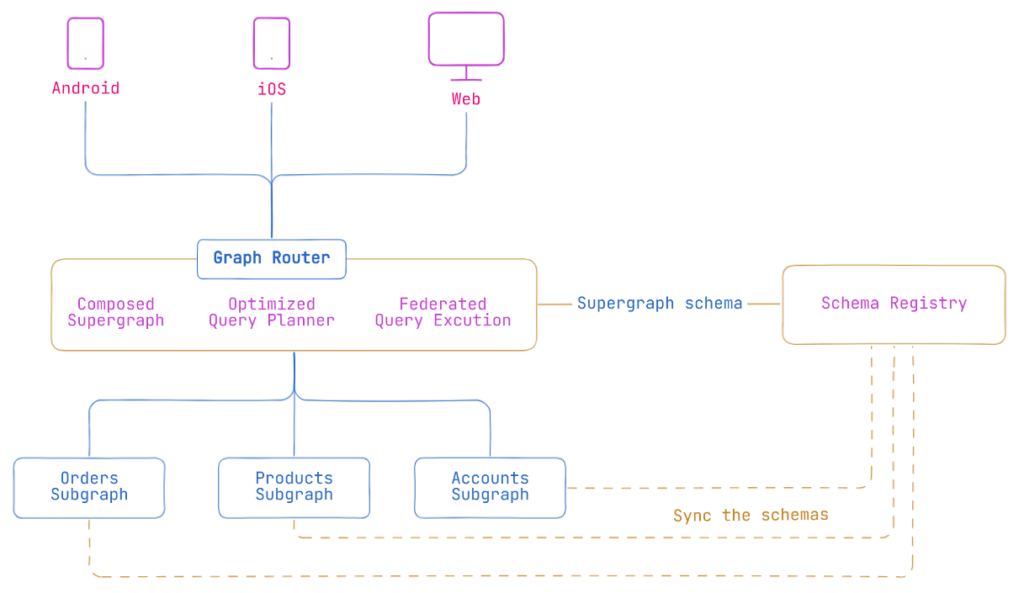
Each microservice in the federated setup defines a part of the overall GraphQL schema related to its domain.
- Subgraphs: These are the smaller parts of the big GraphQL API, each with its own schema, rules, and data sources.
- Gateway (Router): A special component called the gateway federates the subgraphs into one unified API. It routes queries to the appropriate services and aggregates the results
The Benefits of GraphQL Federation
GraphQL Federation offers several benefits, especially for organizations looking to scale their GraphQL APIs across multiple teams and services. Here are some key advantages:
- Decentralization: By splitting the Graph API across multiple services, teams can work independently on different parts of the schema, fostering parallel development and innovation.
- Ease of Scaling: As schemas grow, the federation handles the complexity of combining them, making it easier to scale and deploy new features or updates.
- Flexibility: Federation supports incremental adoption, allowing teams to gradually transition to a federated architecture without a complete overhaul.
- Implementation Independence: With federation, the underlying implementation can vary, supporting different programming languages and frameworks.
- Separation of Concerns: Each subgraph is only responsible for resolving the fields that it contributes to the entity. This adheres to the principle of separation of concerns, allowing different teams to work on their services independently while still contributing to a unified data graph.
- Performance Optimization: By allowing clients to fetch all the data they need in a single request, federation optimizes resource deployment and reduces redundancies.
Core Concepts of GraphQL Federation

GraphQL Federation is a powerful approach for creating a unified GraphQL API from multiple independent GraphQL services. Here are the core concepts:
- Schema Composition
Federation allows for the composition of a single schema from multiple sub-schemas. This enables teams to work independently on their parts of the schema while contributing to the overall graph - Type Extensions
Services can extend types defined in other services. This allows for the creation of relationships between types across different services - Entities and Keys
In a federated GraphQL system, an entity is an object type that you can define in one subgraph and then reference or extend in other subgraphs. Entities are the core building blocks that allow a federated graph to function as a cohesive unit. And to designate an object type as an entity, you apply the@keydirective to it. This directive specifies the fields that uniquely identify an instance of the entity across the federation. For example, aProductentity might have anidfield as its key.
By leveraging these concepts, GraphQL Federation provides a powerful solution for orchestrating data across distributed services, maintaining a single endpoint for all services while supporting a distributed architecture
Entity Resolvers in GraphQL Federation
In essence, entity resolvers are the mechanisms that enable a federated GraphQL architecture to work efficiently. They ensure that despite the distributed nature of the services, the data can be resolved and combined as if it were coming from a single, unified API. Here’s a breakdown of their role and functionality:
- Entities and Keys
- Entities: These are types that can be referenced across different services. They are defined using the @key directive, which specifies the fields that uniquely identify the entity.
- Keys: Fields that uniquely identify an entity. These keys allow the gateway to associate fields from different subgraphs with the same entity instance.
- Reference Resolvers: The entity resolver is a function that’s responsible for fetching an entity by its key when it’s needed by another subgraph. This is how the gateway knows how to retrieve and combine data from different subgraphs that all contribute to the same entity.
- Resolving Across Subgraphs: When a query comes into the federated gateway that requires fields from an entity, the gateway will use the entity’s resolver to fetch the necessary data from the subgraph that owns that part of the entity. This allows the gateway to construct a complete response using data from multiple subgraphs.
Here’s an example of a federated schema that uses entities and resolvers:
# Accounts service (subgraph)
type User @key(fields: "id") {
id: ID!
username: String!
# ... other user fields
}
# Products service (subgraph)
type Product @key(fields: "upc") {
upc: String!
name: String!
price: Int
# ... other product fields
}
# Inventory service (subgraph)
extend type Product @key(fields: "upc") {
upc: String! @external
inStock: Boolean
# ... other inventory fields
}
# Gateway (combines subgraphs)
type Query {
me: User
product(upc: String!): Product
# ... other root fields
}In this example:
- The
UserandProducttypes are defined as entities in their respective services using the@keydirective, which specifies the fields that uniquely identify an instance of the entity across the federation. - The
Producttype is extended in the Inventory service to include additional fields likeinStock, which indicates whether the product is available. The@externaldirective is used to reference theupcfield defined in the Products service. In this case, the Product entity is extended across two subgraphs, and each subgraph contributes different fields. For the Product entity defined above, the reference resolver might look like this:# Products subgraph
const resolvers = {
...
Product: {
__resolveReference(productRepresentation) {
return fetchProductByUPC(productRepresentation.upc);
}
}
}; - The gateway combines these subgraphs into a single schema, providing a unified API for clients to query data from multiple services seamlessly.
Entity resolvers would be implemented in each service to fetch the data for their respective fields when requested through the gateway. This allows for a distributed architecture where each service is responsible for a specific part of the data graph, enabling more efficient development and scalability.
Conclusion
GraphQL Federation is not just a trend; it’s a strategic approach to building scalable, flexible, and manageable APIs. As more companies adopt microservices, federation offers a way to maintain a unified API without the drawbacks of a monolithic setup. With its ability to adapt to growing demands and facilitate team collaboration, GraphQL Federation is poised to be a cornerstone in the future of API development.
References
Learn GraphQL
How Netflix Scales its API with GraphQL Federation
Schema Stitching with Graph Tools