



We’ve all encountered this situation before. Your organization deals with a massive influx of data points on a daily basis. Most days, everything runs smoothly, also Monitoring and Alerting also running well, but occasionally, the pipelines hit a roadblock. Upon investigation, we discover that the issue stems from a single invalid or malformed message. You resolve the problem and put in place a fail-safe mechanism to prevent it from recurring.
Why Fail-safe not yet Implemented
Now, some may wonder why we didn’t implement the fail-safe from the start. As data engineers, we understand the delicate balance between efficiency and providing business value. We have numerous integrations to handle and limited time, so prioritization is essential. Additionally, data is inherently chaotic, making it impossible to guard against every possible mutation. Moreover, each hour spent programming has an associated business cost. Consequently, prioritizing new integrations over a few edge cases is a reasonable approach, as long as we reinforce our safety net around the weakest points. The trouble arises when unverified assumptions lead to issues.
Maintaining this equilibrium between efficiency and robustness is crucial. Delaying complex fail-safe implementations may offer short-term efficiency gains but could lead to problems later. To sustain this delicate balance, two critical components play a pivotal role: monitoring and alerting. Although often overlooked, these elements are essential in identifying silently failing processes within the infrastructure, which can have severe consequences, such as halting the pipeline or compromising data integrity.
The Levels of Monitoring & Alerts
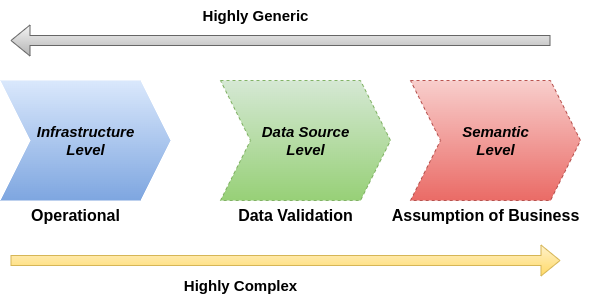
- Operational Alerts:
The first type of alerts focuses on operational issues, ensuring that all systems function smoothly at the service/bare-metal level. For instance, these alerts monitor message queue size and the age of the oldest message, providing a clear picture of our process health. Operations encounter spikes at various points in their lifecycle, leading to potential false alarms or exaggerated importance. Hence, Need to define multiple thresholds, each with its level of significance. Critical alerts require immediate attention, while others can be investigated later. Moreover, low-importance alerts should be examined before they escalate and disrupt other data pipelines.
Without these operational alerts in Monitoring and Alerting, we would be blind to potential issues, and invisible problems could persist for days or weeks unnoticed, causing disastrous consequences. - Data Validation:
Data validation verifies whether specific values are received correctly and whether the volume of data aligns with expectations. Key metrics include:
a. Checking if we received the correct number of files for a given date.
b. Comparing the data volume with the average number of ingested rows from previous days.
c. Validating the successful unzipping/loading of incoming files.
d. Confirming if files arrived at the expected timestamp.
Implementing data validations requires a deeper understanding of the dataset. Unlike operational alerts in Monitoring and Alerting, data validation delves into the semantics of the data, making it more complex. Data validations are invaluable in cases where ingestion issues occur or messages are silently dropped in the infrastructure. Thus, they play a crucial role in a data-driven business. - Business Assumptions:
Once confidence in the data’s presence and correctness within our pipeline,now move on to examining the data’s accuracy. This level of alerting requires in-depth knowledge of the data’s semantics, and the responsible team should be the one that owns the data—usually, the team responsible for ingestion or, in some cases, the consuming team that understands the data better.
Business assumptions cover a wide range of scenarios, including:
a. Assuming the file header always follows a specific date format, but uncertain if this will hold for new files.b.
b. Believing that two values should always add up to a third value. If this assumption fails, subsequent calculations could be compromised.
c. Checking if values in a row align with initial research findings.
d. Verifying if values fall within an expected range and have minimal outliers.1
Implementing these alerts can be challenging, as deciding between warnings and errors requires a comprehensive understanding of the data and its sources. Striking the right balance ensures data quality remains intact without generating an overwhelming number of alerts. When properly implemented, these alerts offer a safety net against inaccurate data, providing valuable insights into assumptions and guiding us in refining valid ones while eliminating faulty ones.
Conclusion
Working with Big Data presents a chaotic landscape. Taming this chaos without insights is a daunting task, as it involves countless edge cases. Incorporating different types of alerts allows us, as engineers, to categorize this chaos into manageable chunks, leading to independent resolutions. Consequently, We can encounter fewer issues and can implement targeted fail-safes, bolstering the robustness of our processes and data.
The hierarchical nature of alerts facilitates delegation of responsibilities among teams, provides a clear understanding of required expertise for each alert level, and indicates implementation complexities at different depths. Depending on the data source, careful consideration should be given to the benefits and costs of introducing specific validations.”