



Introduction
In this era, of self-service business intelligence,each and every company, is considering themselves as a data-first company. But are those companies treating their data architecture with level of scalability, it needs. This need of democratisation and scalability is driving a new architecture pattern and causing the older architecture i.e. a soiled data warehouse or a data lake to obsolete. In this blog, we will discuss about data mesh and topology related to data mesh.
What is Data Mesh?
The current software engineering generation has seen a transition from monolithic applications to micro-service architecture. The data mesh is, in many ways, the data platform version of micro-services.
As first defined by Zhamak Dehghani, the original architect of the term, a data-mesh is a type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design. It is considered that, the design of data-mesh is borrowed from the “domain-driven-design” theory of Eric Evan. The data mesh is widely considered the next big architectural shift in data.
Unlike, the traditional monolithic data infrastructure that handles the consumption, storage,transformation and even output of data in one central lake. The data mesh supports distributed, domain-specific data consumers and views “data-as-a-product”, with each domain building and handling their respective data pipelines. In addition to it, there is a universal interoperability layer that connects these domains and their associated data. This, universal interoperability layer applies the same data standard and same syntax across the pipelines.
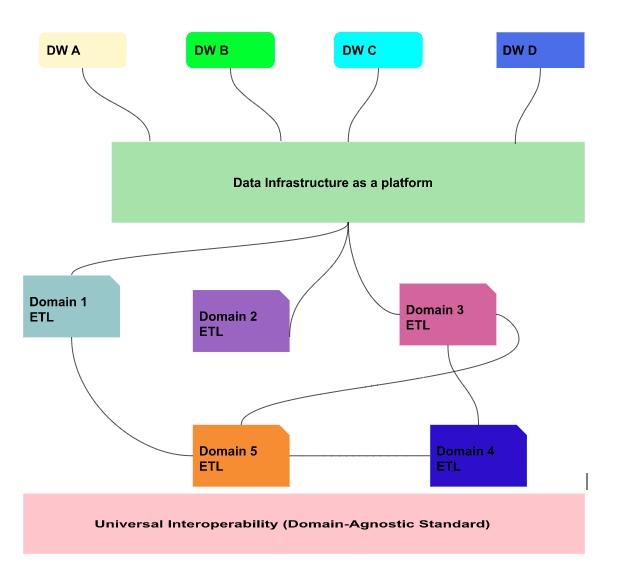
Need of Data Mesh
Till the time, most of the companies created a single data warehouse connected to countless business intelligence platforms. These solutions were maintained by relatively small group of engineers and frequently has technical issues. Later in the era, a new architecture, “Data-lake”, emerged, with real-time data availability and stream processing, In data lake, the ingestion, enrichment, transformation and even serving data occurs from a centralised system. This types of architecture has some issues, a central ETL pipeline gives teams less control over increasing volumes of data. As every company is becoming a data company, different use cases requires different types of transformations, putting a heavy load on the central platform.
Such data lakes, often leads to disconnected data producers, impatient data consumers, and worse of all, backlogged data team struggling to keep the pace with the demands of the business.Instead, domain-driven data architectures, like data meshes, provides both: a centralised database(or a distributed lake) with domains(or business areas) responsible for handling their own pipelines.
Topology in Data Mesh
Fine-grained Fully Federated Mesh
First of all,this design pattern is the pure form of data mesh describe by Zhamak Dehghani. It is fine-grained, highly federated and uses ,many small and independent deployable components. Secondly. in this model, data distribution is peer-to-peer, while the governance-related metadata is logically centralised. In this topology, each individual domain owns, manages and shares data. In addition to it, domains remain flexible and don’t rely on a central team for coordination and data distribution. It offers organisational flexibility and fewer dependencies as the interaction is many-to-many. Finally, it promotes intensive reuse of data science and there’s a high degree of data products creation.
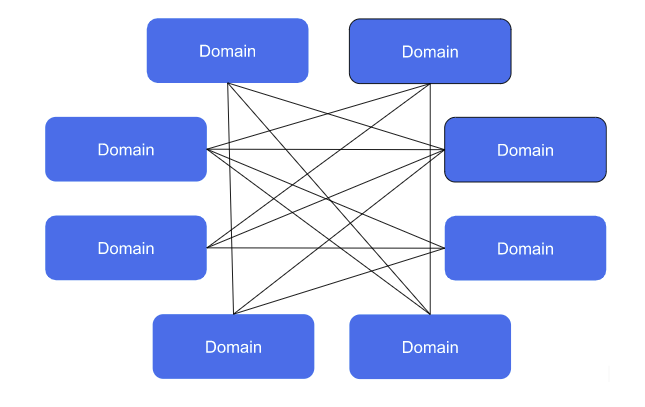
Although, initially, the fine-grained and fully-federated mesh looks good, when look deeper, they raise concerns. First, this topology requires a conformation from all the domains for interoperability, metadata, governance and security standard, defined by other teams. It needs a critical mass and support from the wider audience.
Second, there can be capability duplication and heavy network utilisation. Each data product may increase the number of the infrastructure resources and thus making architecture costly. The granularity of data product architectures also raise concerns, if there is intensive cross-domain lookups and data quality validations. There is a saying in data world, data gravity and decentralisation don’t go hand in hand.
The above architecture is a good choice but hard to achieve. It performs better, when there’s already a high degree of autonomy within company.
Fine-grained and Fully Governed Mesh
To overcome the federation concerns, many companies add a additional central layer of distribution to fine-grained fully federated topology. Though, this topology, differs from traditional data mesh architectures, it does follows many data mesh principles. It defines the clear boundary and ownership for each domain applications and data products. But a central entity distributes those data product.
Even fine-grained and fully governed mesh addresses some concern as observed in the fine-grained fully federated mesh. It addresses data distribution and gravity concerns. like time-variant and non-volatile considerations for large data consumers. Since it persists the data more closely together on a shared storage layer, domains don’t require to distribute large historical datasets.
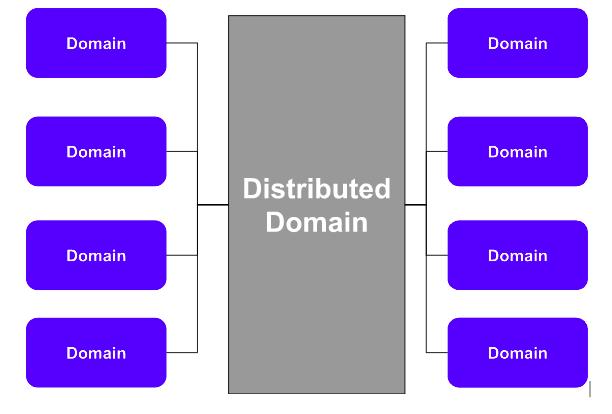
It seems that this topology easily addresses concerns of conformation, Let us say, we can block data distribution or consumption, enforce metadata delivery or require a specific way of working. The multiple-work-spaces-shared-like design is the best practice. Domains manage and create data products in their own work-spaces, but the distribution to other domains occurs through a central storage layer using domain-specific containers.
Apart from offering a central storage layer, companies provide centrally managed compute or processing services as well. Let us say, we can provide domain specific transformations to each domain using dedicated compute but shared pools of compute resources process the historic data. This approach drastically reduce costs.
The topology stronger centralisation and conformation can also cause problems, It will lead to longer time to introduce more coupling across domains. Even the central distribution layer could hinder domains from delivering business value. In addition to it, even this topology can cause trouble on multi-cloud design, as it requires to design a central and distributed logical entity. It can be difficult to build a seamless data movement along with governance standards across multi-clouds.
Mostly the companies that needs fully governed architectures, uses this topology, like financial institutions and governments. These companies value quality and compliance over agility.
Conclusion
In this blog, we discussed above data mesh and need for the data mesh along with the two kinds of topology offered in data mesh. Apart from above topology, there are four other topology like Hybrid Federated Mesh, Value Chain Aligned Mesh, Coarse Grained Aligned Mesh and Coarse Grain Governed Mesh, which we will discuss in next blog.