



Nowadays, when the development speed of Data projects becomes too fast, it requires continuous integration and delivery to users. This development comes with gaps in the preparation of the environment, as well as the security of data products. This article aims to introduce, define and explain the importance of a project member with the title “DataOps”.
1. Introduction to DataOps
DataOps is an emerging data management discipline that is getting a lot of traction and on the rise according to Gartner, Inc. There are many DataOps definitions across thought leaders in this space, IBM, Gartner, Eckerson Group, Forbes and DataKitchen. Based on these sources, DataOps is the orchestration of people, processes, and technology to accelerate the quick delivery of high-quality data to data users.

Firgure 1: DataOps Decipline. Source: Atlan
A collaborative data management practice focused on improving the communication, integration and automation of data flows between DataOps’ managers and DataOps’ consumers across an organization. Data can be thought of as a product created via an assembly line of phases such as Information Architecture, Development, Orchestration, Testing, Deployment and Monitoring. Throughout each phase the goal is to deliver high-quality data with speed.
2. Why DataOps becomes important in Data Projects?
DataOps promises to streamline the process of building, changing, and managing data pipelines. Its primary goal is to maximize the business value of data and improve a client’s experience in data delivery. It does this by speeding up the distribution of data for reporting and analytic output, while simultaneously reducing data defects and lowering costs.
DataOps is used for building analytic solutions, including reports, dashboards, self-service analytics, and machine learning models. It emphasizes the effective collaboration across teams that handle different pieces of a data pipeline, while keeping an overarching view.
DataOps applies the rigor of software engineering to the development and execution of data pipelines, which govern the flow of data from source to consumption. It leverages principles from successful frameworks with a data spin (DevOps, Agile and Statistical Process Control). By delivering data “faster, better, and cheaper,” data teams increase the business value of data and customer satisfaction.
3. How did DataOps become an important role in the Data project?
Similar to an assembly line that manufactures cars, a DataOps assembly line excels in increased efficiencies, speed and reduced costs to produce quality data products. As data progresses through its lifecycle, DataOps ensures the right best practices and controls are in place such as:
- Continuous integration and delivery
- Data quality and resolution with data observability
- Audibility with data/code versioning
- Automated orchestration
- Reusability with implementing everything as an asset
- Effective collaboration across data roles
To implement DataOps there are a series of phases, criteria and best practices that come into play. This sits on a foundational layer of Data Governance which is incorporated in the DataOps assembly line.
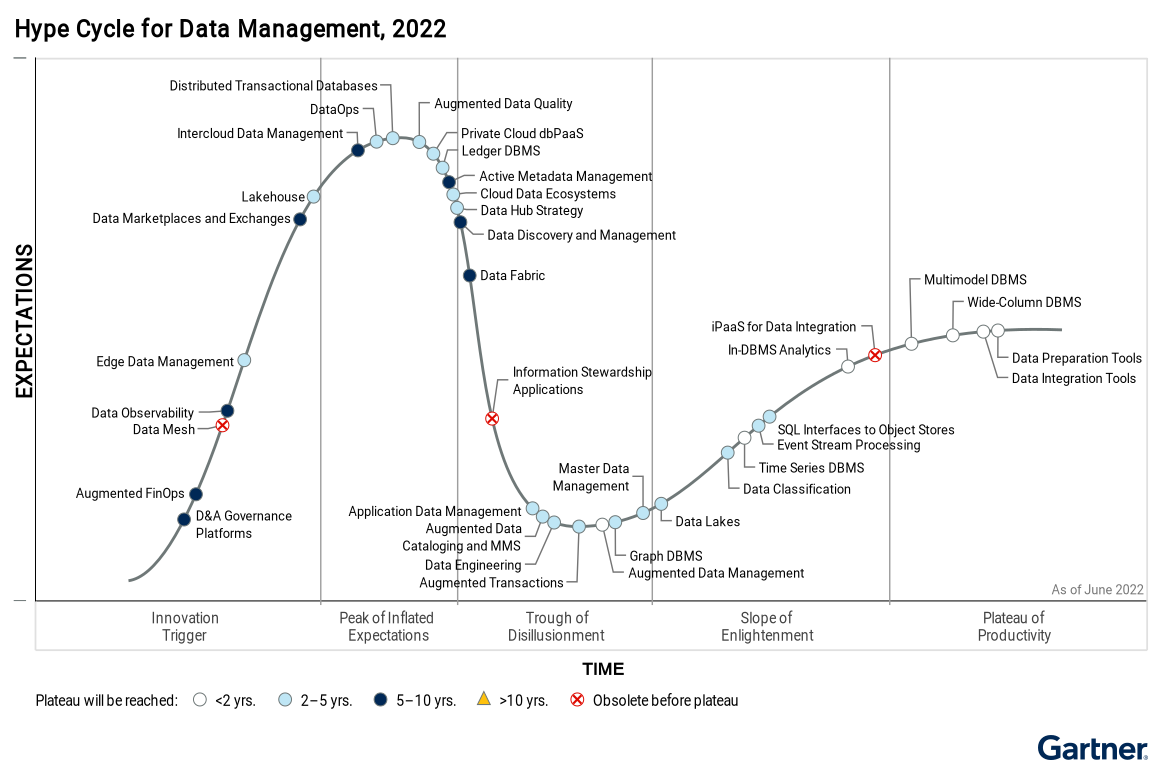
According to Gartner’s Hype Cycle for data management 2022, the demand for DataOps is at its peak right now when in fact very few DataOps teams exist in Data projects, or we are simply mistaken that technologies can act as Ops for a Data Project Team. Follow the increasing momentum in the development of medium, large and enterprise Data projects will lead to the need to develop a DataOps skillset group, which requires first the correct identification of DataOps and reasonable allocation. resources for the implementation of Ops activities to be reasonable and timely.
4. Key Differences between DataOps and DevOps
| DataOps | DevOps |
| Makes sure that data is reliable, trustworthy, and not broken | Makes sure that the website or software (mainly backend) is not broken with addition, alteration, or removal of code |
| DataOps’ ecosystem consists of databases, data warehouses, schemas, tables, views, integration logs from other key systems | Here CI/CD pipelines are built, automation of code is discussed, and uptime & availability are improved constantly |
| Continuous integration and delivery for data pipelines. | Continuous integration and delivery for software. |
| Focuses on data processing and analytics. | Focuses on software development and deployment. |
| It ensures smooth collaboration between data analysts, engineers, and other data-focused roles. | It ensures effective collaboration between development and operations teams. |
| Streamline data pipeline performance and monitoring. | Emphasis on application performance and monitoring. |

5. DataOps Activities – Observation from Engineering Perspective
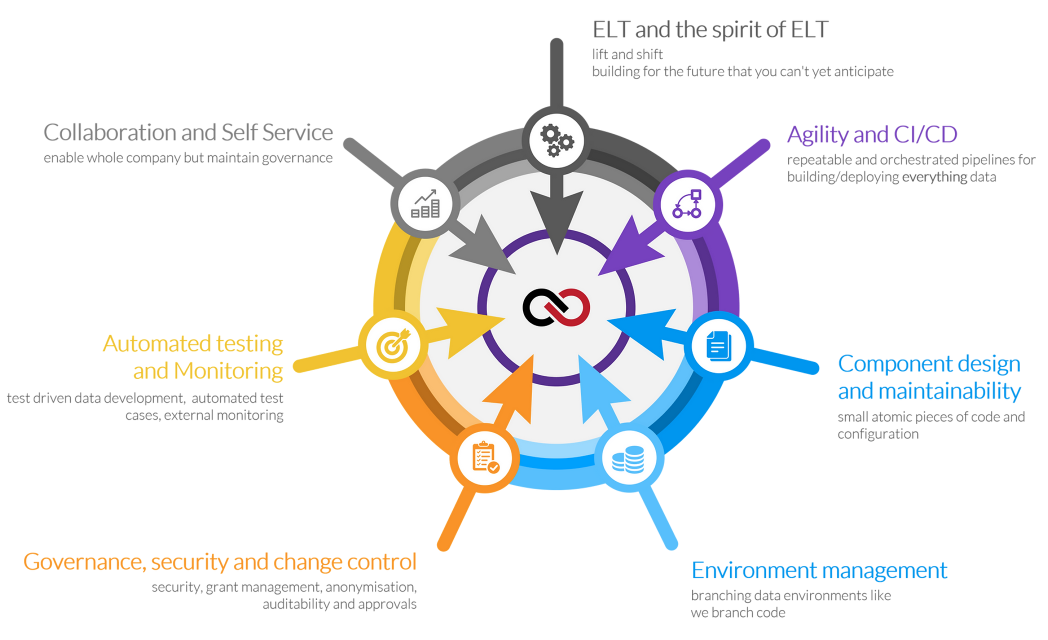
Step 1: Environment Management
- Gather information from the Product Owner about the functions, tasks, and specifics of each environment.
- List project members working on each environment.
Step 2: Component design & maintenance
- Based on the requirements from the Product Owner, build the corresponding components according to each Data Product, fine-tuning for each environment to meet the needs of product development in each stage.
Step 3: Collaboration
- Communication to share engineering efforts among Data Teams
- Contact with System/DevOps Teams in case of Deployment Process.
Step 4: Extracts, Loads, and Transformations
- Work closely with Business Analysts and Business Users to understand the business requirements to serve the goal of defining the data structure in the product.
- Join with Data Engineers and Data Analysts in developing data product modules and functions.
Step 5: Automated Testing and Monitoring
- Based on the requests received from the Business Analyst and turn the requirements into rules for the data monitoring system to warn the development team when errors arise to minimize the developers’ effort to implement. Unit Test.
- At the same time, configure monitoring systems for the purpose of observing product activities
Step 6: Continuous Integration & Continuous Deliveries
- Build and initialize parameters for each environment to create inheritance between environments.
- Build pipelines to create continuity and connectivity between the tasks that occur in each environment and between environments.
Step 7: Governance, Security, and change control
- Set limits for each end user to ensure that sensitive data is shared appropriately and to the right audience.
- Initiate security protocols between each data product component, and also monitor security policy changes and updates over the time.
However, at some steps of the DataOps activity can be flexibly changed depending on the nature of the project, in order to meet the special needs of the project team following the implementation with Agile Methodology.
6. DataOps vs Non-DataOps Projects
In the spirit of Data projects, the project needs inspiration to bring the fastest and most timely products to the clients, however, sometimes the DevOps team is too busy to handle the extremely complex requirements of the Data Team, the emergence of DataOps is essential, when having a role that both understands Data Processing and masters the infrastructure, for NashTech’s competencies, they were empowered with NashTech Data Accelerator, this tool helps DataOps to create 1 or multiple infrastructure groups in minutes. In addition, for the specificity of Data projects, deliverable products will appear with a fairly dense frequency or sometimes have quite tricky requirements in terms of permission or authorization that normal DevOps can’t anticipate. , this does not come from the infrastructure or the environment, but sometimes comes from the internals of the Data product, so it will take a lot of time to explain or analyze, which makes the development speed of the project slow down. In addition, for security, safety and data governance, DevOps cannot cover it all, but it must rely on someone who understands Data to be able to analyze and evaluate the priority of data or the importance of data. in order to be able to coordinate with Data Owners to set out appropriate policies to contribute to data cleaning, reasonable data allocation, and ensure that data is stored and properly used for the right purposes and for the right users. statue.
7. Conclusion
In short, DataOps here is not just a technology, it is a combination of many technologies, mindsets, knowledges, experiences, and skills. From the early 2020s onwards, not only Ops but also DataOps had become one of the leading trends that any project needs to help the project be fully delivered to the end-users , timeliness, and maximum cost optimization for businesses.