



What is Delta Lake?
Delta Lake is an open-source storage layer that brings reliability and performance improvements to big data processing on top of cloud-based data lakes.
It is open-source software that extends Parquet data files with a file-based transaction log for ACID transactions and scalable metadata handling.
Delta Lake integrates tightly with Apache Spark APIs and tightly integrates with Structured Streaming, enabling you to effortlessly utilize a single data copy for both batch and streaming operations, while also delivering incremental processing at scale.
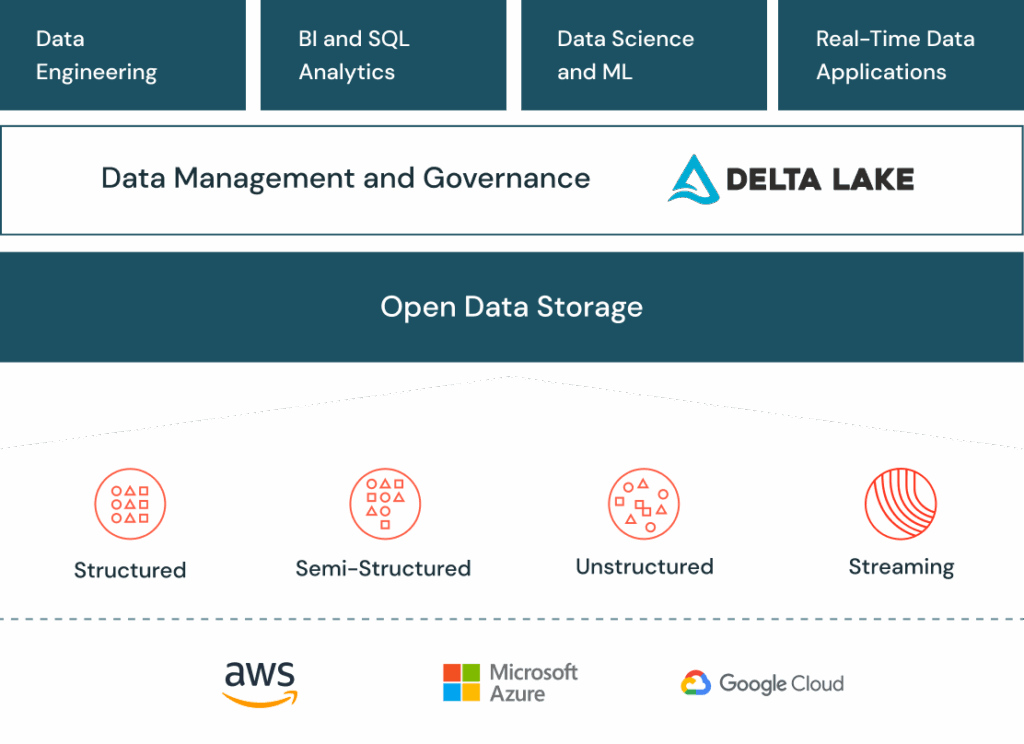
Why Delta Lake?
- Prevent Data Corruption
Delta Lake allows for ACID-compliant reads and writes by keeping a transaction log on file in addition to the data. This avoids data corruption, which is particularly problematic in cloud contexts where future consistency characteristics may arise. Delta Lake’s commit mechanism handles concerns related to cloud storage transactions, ensuring consistency even if an ETL process fails before completing. - Faster Queries
When compared to standard Parquet, Delta Lake improves query performance. Every query no longer requires costly LIST operations on blob storage since the transaction log acts as a manifest. The transaction log’s centralised statistics, like column min and max values, enable data skipping based on query predicates. ZORDER reorganisation is one technique that helps to further increase query speed. - Increase Data Freshness
Delta Lake supports both batch and streaming ingestion use cases. It integrates checkpointing into Structured Streaming with Delta Lake, facilitating data transformations between different Delta Tables. This enables real-time data streaming by enabling more frequent data refreshes. The OPTIMISE command in Delta Lake enhances query performance downstream by compressing tiny data. - Reproduce ML Models
With the help of Delta Lake’s Time Travel function, machine learning models may be repeated by querying data as it existed at a particular moment in time. Replicating a model’s output is essential for data scientists, particularly in situations when the data scientist who trained the model is no longer available. This capability is enhanced by Databricks’ MLflow, which keeps account of the parameters, environment, libraries, and logic utilised during model training. - Achieve Compliance
The DELETE and UPDATE operations in Delta Lake facilitate the management and manipulation of data in a table. This is especially crucial for adherence to recent laws such as the CCPA and GDPR, which require businesses to promptly update or delete personal information at the request of an individual. The features of Delta Lake make these tasks easier while guaranteeing that table queries are not adversely affected.
How it works?

On top of the current cloud storage data lake, delta lake offers a storage layer. It serves as a mediator between cloud storage and Spark runtime. By default, data stored as a delta table is saved in your cloud storage as a parquet file.
Delta logs will be produced by Delta Lake for every transaction that is committed. Under delta logs, delta files will be saved in JSON format. These files will contain details about the most recent file snapshot, operations that took place, and data statistics. The log of all modifications made to a table is composed of delta files, which are named JSON files that increase consecutively.

What are the features and benefits of Delta Lake?
- ACID Transactions
Delta Lake provides Atomicity, Consistency, Isolation, and Durability (ACID) transactions, ensuring data integrity even in the presence of concurrent read and write operations. This is crucial for maintaining the reliability of data in large-scale processing environments. - Batch and Streaming Support
Delta Lake supports both batch and streaming data workloads. This flexibility allows organizations to build data pipelines that can handle various types of data processing requirements. - Schema Enforcement and Evolution
Delta Lake supports schema enforcement, ensuring that data written to the lake adheres to a predefined schema. It also allows for schema evolution, enabling changes to the schema over time as data evolves. - Data Versioning
Delta Lake supports data versioning, allowing organizations to track different versions of the data. This feature is valuable for auditing purposes, as well as for reverting to previous versions of the data if needed. - Time Travel
Delta Lake provides time travel capabilities, enabling users to query the state of the data at a specific point in time. This is useful for historical analysis, auditing, and data debugging. - Unified Batch and Streaming Processing
Delta Lake enables a unified approach to processing both batch and streaming data. This is particularly important in scenarios where data is continuously flowing into the data lake. - Optimized File Management
Delta Lake includes features such as file compaction and Z-ordering to optimize file storage, improving query performance and reducing storage costs. - Metadata Management
Delta Lake maintains metadata that helps track changes, manage transactions, and provides insights into the structure and evolution of the data stored in the lake. - Optimized for Cloud Data Lakes
Delta Lake is designed to work seamlessly with popular cloud-based data lakes, facilitating easy integration into existing cloud environments.
Delta Lakes vs. Data Lake
Data Lake
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. The sheer volume and variety of information in a data lake can make analysis cumbersome and, without auditing or governance, the quality and consistency of the data can be unreliable.
Delta Lake
Delta Lake evolved as an answer to the drawbacks of conventional data lakes in order to solve these problems. In essence, Delta Lake is an open-source storage layer that gives data lakes ACID (Atomicity, Consistency, Isolation, Durability) operations. Popular data processing engines like Apache Spark and Presto are compatible with it because it operates on top of the current data lake architecture.
Some insights into how businesses can leverage Delta Lake for better data management
- Reliable Data Processing:
- Scenario: Imagine a retail business that collects a massive amount of sales data from various sources.
- Insight: Delta Lake’s ACID transactions ensure reliable and consistent data processing. This is crucial for businesses where accurate transactional data is essential, such as maintaining a reliable record of sales transactions.
- Schema Evolution for Data Flexibility:
- Scenario: A telecommunications company constantly adds new features to its services, resulting in changes to customer data structures.
- Insight: Delta Lake’s support for schema evolution allows businesses to evolve their data structures over time without disrupting existing workflows. This flexibility is valuable in dynamic business environments.
- Data Versioning for Auditing and Compliance:
- Scenario: A financial institution needs to maintain a historical record of customer transactions for auditing purposes.
- Insight: Delta Lake’s data versioning capabilities enable businesses to track changes to datasets, providing a reliable audit trail. This is essential for compliance, allowing businesses to demonstrate data integrity and compliance with regulatory requirements.
- Efficient Metadata Management:
- Scenario: A healthcare organization deals with large datasets of patient records and medical history.
- Insight: Delta Lake’s metadata management optimizes data operations, making it easier to manage and analyse large datasets efficiently. This is crucial for healthcare analytics, where quick access to relevant patient information is essential for decision-making.
- Concurrency Control for Collaborative Workflows:
- Scenario: An e-commerce platform has multiple teams working on analytics and reporting concurrently.
- Insight: Delta Lake’s concurrency control ensures that multiple teams can work on the same dataset simultaneously without conflicts. This is beneficial for collaborative workflows, where different business units need to access and analyze the data concurrently.
- Unified Batch and Streaming Processing:
- Scenario: A media company receives both batch data (content uploads) and streaming data (user interactions) for content analytics.
- Insight: Delta Lake’s support for both batch and streaming data processing provides a unified platform. Businesses can seamlessly integrate batch and streaming data for real-time analytics, allowing them to make timely decisions based on the latest information.
By incorporating Delta Lake into their data lakes, businesses can achieve better data quality, reliability, and manageability, leading to improved decision-making processes and business outcomes.
To get started with Delta Lake, you can visit delta lake tutorial
For more blogs please visit NashTechBlogs