


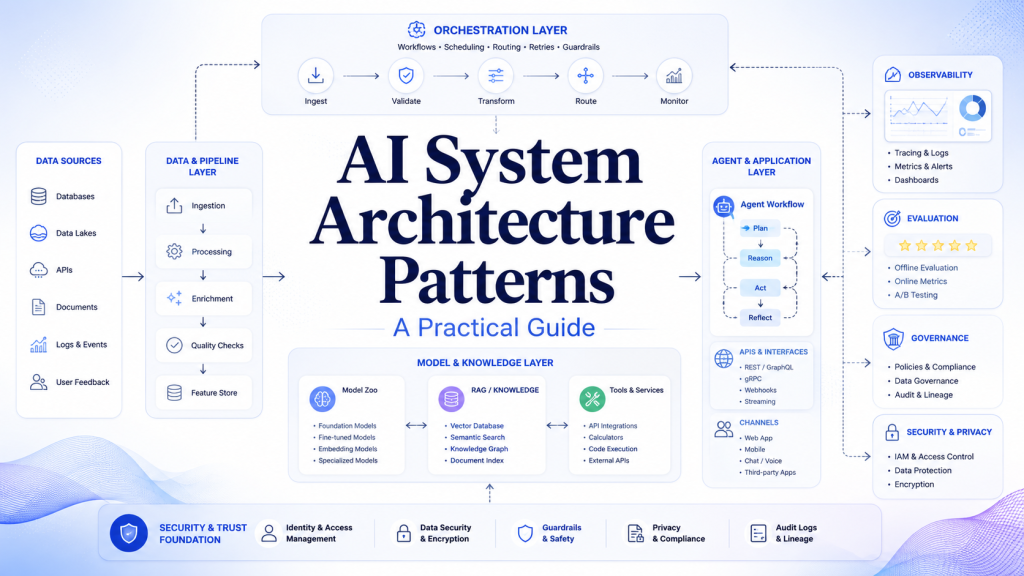
Introduction
AI systems are no longer simple experiments built around a single model. In production environments, they need data pipelines, inference services, orchestration logic, monitoring, evaluation, security controls, and governance. This is why AI System Architecture Patterns are important for software architects, AI engineers, and technical teams that want to build reliable AI applications.
A model may be powerful, but the surrounding architecture decides whether the system can scale, remain secure, control costs, and produce useful results in real-world workflows. For example, a fraud detection system needs low-latency inference. A knowledge assistant needs retrieval-augmented generation. A manufacturing system may need edge AI. Meanwhile, a legal review assistant may require human approval before any final decision.
AI System Architecture Patterns provide reusable solutions for these recurring design problems. They help teams select the right structure for the right use case instead of forcing every AI workload into the same architecture.
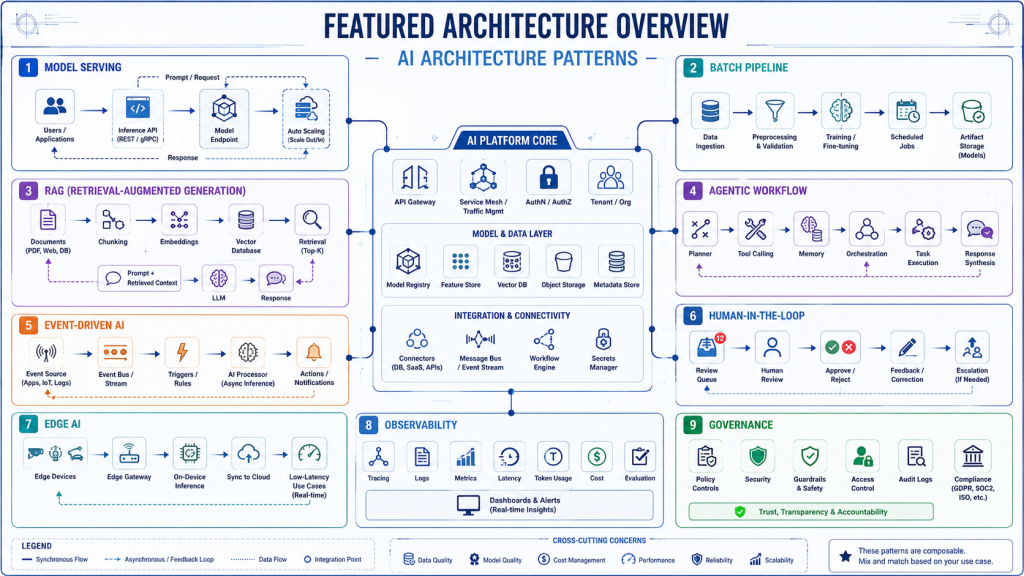
What Are AI System Architecture Patterns?
AI System Architecture Patterns are reusable system designs for building AI-enabled applications. They describe how data flows through the system, how models are served, how inference is triggered, how workflows are orchestrated, and how outputs are monitored or reviewed.
These patterns are different from model architecture. Model architecture refers to the internal structure of an AI model, such as neural network layers, attention mechanisms, or training methods. In contrast, AI system architecture focuses on the complete software environment around the model.
A typical AI system may include data sources, batch or streaming pipelines, feature stores, vector databases, inference APIs, workflow orchestration, application backends, monitoring tools, and governance controls. The chosen pattern depends on the problem being solved.
For example, a recommendation engine may use real-time model serving. A monthly customer segmentation process may use a batch pipeline. An enterprise chatbot may use retrieval-augmented generation. A security monitoring platform may use event-driven AI.
Why AI System Architecture Patterns Matter
AI System Architecture Patterns matter because production AI systems must satisfy more requirements than model accuracy alone. They must handle latency, scalability, reliability, privacy, explainability, observability, and cost.
During early prototyping, teams often focus mainly on choosing the best model. However, production systems introduce additional questions. How fresh must the data be? How fast must the response be? Who can access the output? How are errors detected? How are decisions audited? How does the system recover from failure?
Architecture patterns help answer these questions. They give teams a proven structure for common AI workloads. As a result, teams can build faster, avoid repeated design mistakes, and create systems that are easier to operate.
Good architecture also improves maintainability. When data, models, orchestration, application logic, and monitoring are separated clearly, each layer can evolve independently. This modularity is essential because AI tools, models, and deployment platforms change quickly.
Core Components Behind AI System Architecture Patterns
Most AI System Architecture Patterns share several common components. The arrangement of these components changes depending on the use case, but the building blocks are often similar.
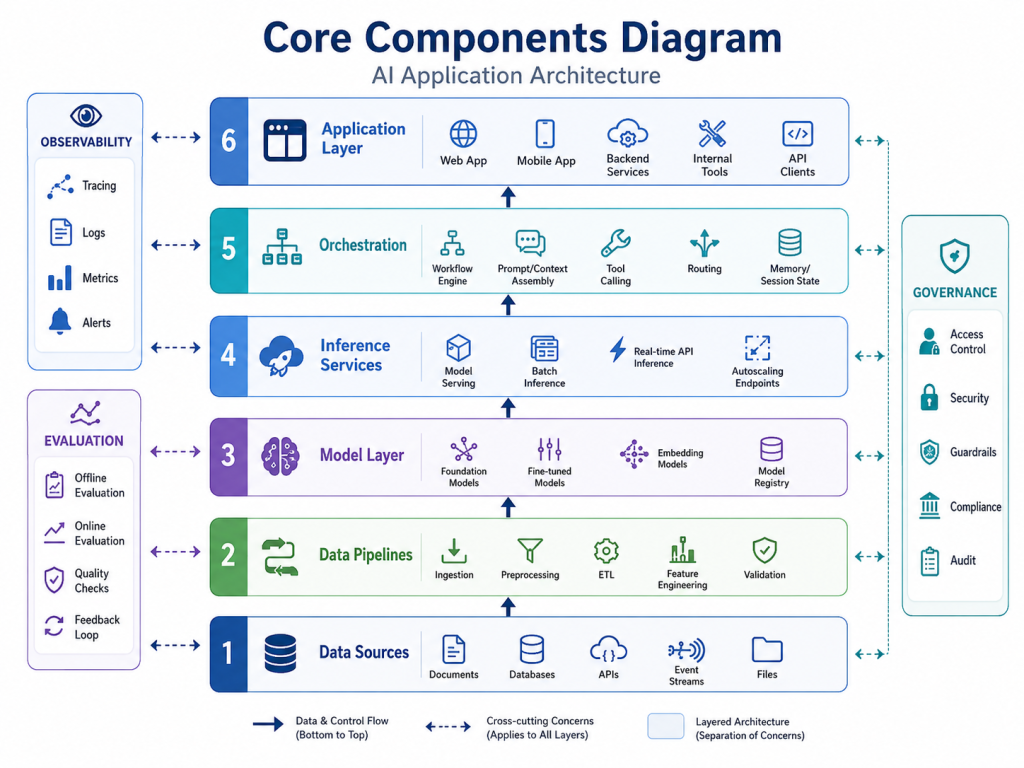
Data Sources and Data Pipelines
AI systems depend on data. Data may come from databases, documents, logs, user interactions, APIs, images, audio, sensors, or event streams. Before the model can use this data, the system often needs to clean, transform, validate, and enrich it.
Some workloads use batch pipelines. These pipelines process data on a schedule, such as hourly, daily, or monthly. Other workloads use streaming pipelines, where events are processed continuously as they arrive.
Data quality is critical. If the data is incomplete, stale, duplicated, or biased, the model output may become unreliable. Therefore, data validation and freshness checks should be part of the architecture.
Model Layer and Inference Services
The model layer contains the AI models used by the system. These may include classification models, regression models, recommendation models, ranking models, embedding models, computer vision models, or large language models.
Inference services expose these models through APIs or internal services. They handle request formatting, model execution, response parsing, scaling, and error handling.
In production, teams may use hosted models, self-hosted models, or a hybrid approach. Some systems also use model routing, where different requests go to different models based on cost, latency, accuracy, or task complexity.
Application and Orchestration Layer
The application layer connects AI capabilities to users and business workflows. It may include web applications, mobile apps, dashboards, chat interfaces, backend APIs, or internal automation tools.
The orchestration layer coordinates the workflow. It decides when to call a model, when to retrieve context, when to call an external tool, and when to apply validation rules. This layer is especially important for generative AI and agentic systems, where one request may involve multiple steps.
Clear orchestration prevents the model from becoming responsible for everything. Business rules, access control, retries, fallbacks, and deterministic operations should remain in software logic.
Observability, Evaluation, and Governance
Observability helps teams understand system behavior in production. It includes logs, metrics, traces, alerts, and dashboards. For AI systems, observability should monitor latency, errors, model quality, drift, token usage, cost, and business impact.
Evaluation measures whether the AI system performs well. It may include test datasets, benchmark scenarios, human review, feedback loops, and regression tests. Evaluation should happen before deployment and continue after release.
Governance ensures that the system follows security, privacy, compliance, and responsible AI requirements. It may include access control, audit logs, policy enforcement, data retention rules, and human approval for high-impact decisions.
Pattern 1: Model Serving Architecture Pattern
The model serving pattern is one of the most common AI System Architecture Patterns. In this design, an application sends a request to a model endpoint, receives a prediction or generated output, and uses that result in a user-facing or backend workflow.
This pattern is useful when the application needs real-time or near-real-time inference. Common use cases include fraud detection, recommendation systems, customer support routing, risk scoring, image classification, and personalization.
A model serving architecture usually includes an API gateway, inference service, model runtime, monitoring layer, and response handler. For high-traffic workloads, it may also include autoscaling, caching, load balancing, and fallback models.
The main design challenge is balancing latency, cost, and accuracy. A larger model may produce better results, but it may also increase response time and infrastructure cost. Therefore, production systems often use caching, batching, model optimization, or model routing.
Pattern 2: Batch AI Pipeline Pattern
The batch AI pipeline pattern is designed for workloads that do not require immediate responses. Instead of processing one request at a time, the system processes large amounts of data on a schedule.
This pattern is useful for customer segmentation, demand forecasting, risk scoring, inventory analysis, document classification, report generation, and periodic recommendation updates.
A batch AI pipeline usually starts with data extraction. The system then transforms the data, applies feature engineering, runs batch inference, stores the results, and generates reports or downstream updates.
The main advantage of this pattern is efficiency. Since the workload is not time-sensitive, the system can process data in large batches and optimize for throughput. However, the trade-off is freshness. If the batch runs once per day, the output may not reflect real-time changes.
Pattern 3: Retrieval-Augmented Generation Pattern
Retrieval-Augmented Generation, or RAG, is a key pattern for generative AI systems. It allows a language model to generate responses using external knowledge rather than relying only on its internal training data.
A RAG architecture usually includes document ingestion, text chunking, embedding generation, vector database indexing, retrieval, prompt construction, and answer generation. When a user asks a question, the system retrieves relevant content and passes it to the LLM as context.
This pattern is useful for enterprise search, internal knowledge assistants, policy assistants, technical support, legal research support, and product documentation chatbots.
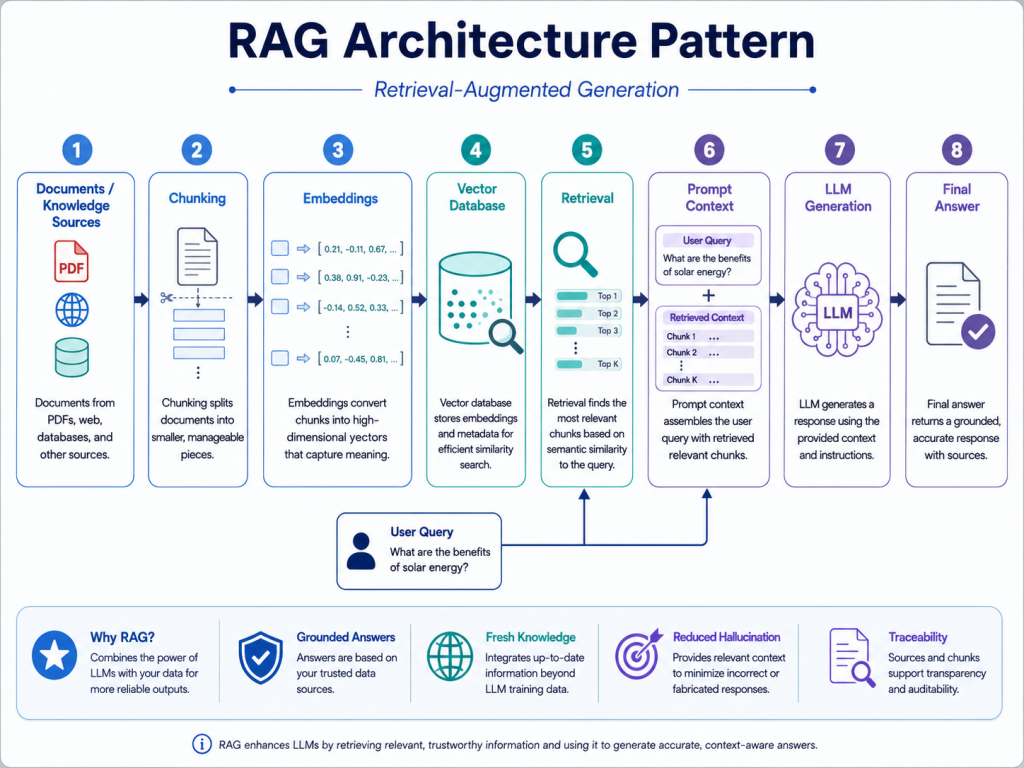
RAG improves answer grounding, but it does not remove the need for good architecture. The system still needs access control, source tracking, retrieval evaluation, and output validation. If the retrieval layer returns poor context, the model may still generate a weak or incorrect answer.
Pattern 4: Agentic AI Workflow Pattern
The agentic AI workflow pattern is used when an AI system needs to complete multi-step tasks. Instead of only answering a question, the system may plan steps, call tools, retrieve data, analyze information, and produce a final result.
For example, an IT operations assistant may inspect logs, check service status, search documentation, suggest a fix, and create an incident ticket. A data analysis assistant may inspect a dataset, generate a query, run the query, summarize results, and create a chart.
This pattern usually includes an orchestration layer, tool registry, memory or state management, permission checks, model calls, and audit logs. The model may help reason about the next step, but the application should control which tools are available and what actions are allowed.
Agentic workflows need clear boundaries. Without constraints, an autonomous system may take unnecessary actions, call unsafe tools, or produce difficult-to-audit behavior. Therefore, bounded autonomy, approval gates, and logging are essential.
Pattern 5: Event-Driven AI Architecture Pattern
The event-driven AI architecture pattern uses events to trigger AI processing. Instead of waiting for a direct user request, the system reacts when something happens.
For example, a security system may analyze login events for suspicious behavior. A manufacturing system may inspect sensor events for anomalies. An e-commerce platform may update personalization based on user activity. An operations platform may classify alerts and route incidents.
This pattern usually includes event producers, message queues, event streams, AI workers, inference services, and downstream actions. It is useful when the system must respond to continuous signals.
The key benefit is responsiveness. The AI system can react quickly to changing conditions. However, event-driven architectures require careful design around retries, duplicate events, ordering, backpressure, and failure handling.
Pattern 6: Human-in-the-Loop AI Pattern
The human-in-the-loop pattern adds human review, approval, correction, or escalation into the AI workflow. It is especially important when AI outputs affect high-impact decisions.
Use cases include medical review support, legal document analysis, financial risk assessment, hiring workflows, content moderation, compliance review, and enterprise approvals.
In this pattern, the AI system may generate a recommendation, classify a case, summarize evidence, or propose an action. A human reviewer then verifies the output before the final decision is made.
Human-in-the-loop design improves safety and accountability. It also creates useful feedback data for improving the system. However, teams must design the review workflow carefully. Reviewers need context, explanations, source references, and clear decision options.
Pattern 7: Edge AI Architecture Pattern
The edge AI architecture pattern runs AI inference near the device, user, or data source instead of relying entirely on a central cloud service.
This pattern is useful when latency, privacy, bandwidth, or offline availability matters. Common use cases include IoT devices, smart cameras, robotics, mobile AI features, industrial inspection, and autonomous systems.
An edge AI system may include local sensors, an optimized model, device runtime, local storage, synchronization logic, and cloud-based monitoring. Some systems perform inference locally and send only summarized results to the cloud.
The main design challenge is resource limitation. Edge devices may have limited memory, compute power, battery life, and network connectivity. Therefore, models often need compression, quantization, or hardware-specific optimization.
Pattern 8: AI Observability and Evaluation Pattern
The AI observability and evaluation pattern supports every other pattern. It helps teams understand whether the AI system is working correctly after deployment.
Traditional software monitoring tracks latency, errors, and infrastructure health. AI observability must go further. It should also track prediction quality, model drift, data drift, retrieval quality, prompt behavior, token usage, cost, and user feedback.
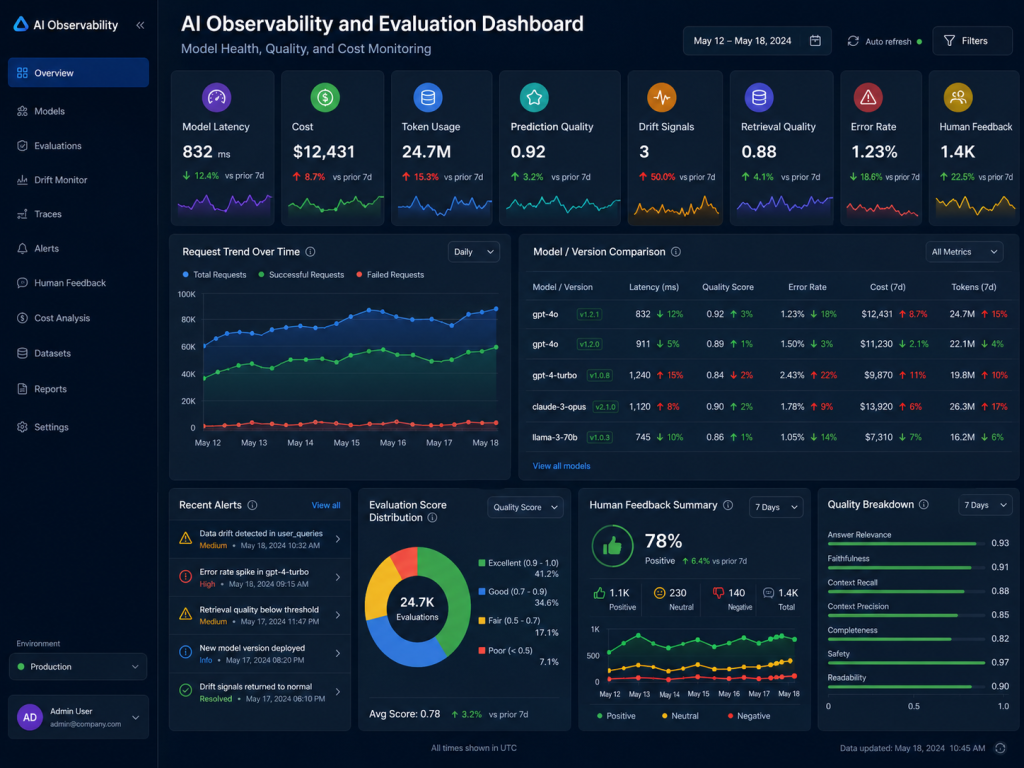
Evaluation should include both offline and online methods. Offline evaluation uses test datasets and expected outputs before deployment. Online evaluation uses real production signals such as user feedback, human review results, conversion rates, escalation rates, or business outcomes.
This pattern is not optional for production AI. Without observability and evaluation, teams may not know when model quality declines, data changes, or costs increase unexpectedly.
How to Choose the Right AI System Architecture Pattern
Choosing the right pattern depends on the problem, not the model. A good architecture starts with the workflow, data flow, latency requirement, risk level, and operational constraints.
For real-time predictions, the model serving pattern is usually appropriate. For large scheduled workloads, the batch AI pipeline pattern is a better fit. For knowledge-heavy generative AI, RAG is often the right starting point.
For multi-step tasks, an agentic AI workflow may be useful. For continuous signals, event-driven AI is more suitable. For high-impact decisions, human-in-the-loop architecture is important. For device-local processing, edge AI is the better option.
In many production systems, teams combine several patterns. For example, an enterprise support assistant may use RAG for knowledge retrieval, model serving for classification, agentic workflow for ticket creation, human review for escalations, and observability for monitoring quality.
Common Mistakes in AI System Architecture
Starting With the Model Instead of the Workflow
A common mistake is choosing a model before understanding the workflow. The team may select a powerful model but later discover that the system needs real-time inference, strict access control, human review, or event-driven processing.
The better approach is to start with the business process and data flow. Once the workflow is clear, the team can select the right model and architecture pattern.
Ignoring Monitoring and Evaluation
Another mistake is treating deployment as the final step. AI systems can degrade after release because data changes, user behavior shifts, documents become outdated, or model providers update behavior.
Monitoring and evaluation should be part of the architecture from the beginning. Teams should define quality metrics, collect telemetry, review failures, and run regression tests before major changes.
Overusing One Pattern for Every Use Case
No single pattern fits every AI workload. RAG is useful for knowledge-grounded answers, but it is not the right design for every prediction problem. Agentic workflows are powerful, but they may be unnecessary for simple classification. Edge AI is valuable for low-latency device scenarios, but it adds deployment complexity.
Good architecture requires pattern selection, not pattern obsession.
Treating Governance as an Afterthought
Governance should not be added only after the system is deployed. AI systems may process sensitive data, affect important decisions, or generate outputs that need review.
Access control, audit logs, policy enforcement, data retention, and human approval should be designed early. This is especially important in regulated or enterprise environments.
Best Practices for Production AI Architecture
A strong production AI architecture should begin with clear requirements. Teams should define the user workflow, data sources, latency targets, risk level, security needs, and success metrics before selecting the model.
The architecture should separate data, model, orchestration, application, monitoring, and governance layers. This separation makes the system easier to test, operate, and improve.
Teams should also design for observability from the beginning. Logs, traces, metrics, feedback, and evaluation results help engineers understand how the system behaves in production.
For generative AI systems, retrieval and guardrails often matter as much as the model itself. The system should retrieve trusted context, validate outputs, protect sensitive information, and restrict tool access.
Cost optimization should also be part of the design. Caching, batching, model routing, autoscaling, and prompt or input optimization can reduce unnecessary spending without sacrificing quality.
Finally, production AI architecture should remain modular. Models, tools, frameworks, and infrastructure options change quickly. A modular design allows teams to replace components without rebuilding the entire system.
Conclusion
AI System Architecture Patterns help teams design reliable, scalable, observable, and secure AI applications. They provide reusable structures for common production needs such as model serving, batch processing, RAG, agentic workflows, event-driven processing, human review, edge deployment, and observability.
The most important lesson is that AI architecture should start with the system, not only the model. A successful AI application needs clean data flow, stable inference services, clear orchestration, monitoring, evaluation, security, and governance.
By understanding and applying the right AI System Architecture Patterns, technical teams can move from isolated prototypes to production AI systems that are easier to maintain, audit, scale, and improve.
References
https://docs.cloud.google.com/architecture/genai-overview
https://docs.cloud.google.com/architecture/rag-reference-architectures
https://docs.cloud.google.com/architecture/agentic-ai-overview
https://learn.microsoft.com/en-us/azure/architecture/ai-ml
https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview
https://aws.amazon.com/blogs/compute/serverless-generative-ai-architectural-patterns
https://docs.aws.amazon.com/wellarchitected/latest/generative-ai-lens/generative-ai-lens.html