



Key takeaways:
Delta Lake, an optimized storage layer, offers advantages like ACID transactions, schema enforcement, and data versioning. Connecting to Delta Lake may be a challenge for many data engineers. This article introduces a straightforward solution using the widely adopted and popular Python and FastAPI framework.
Introduction Delta Lake
Delta Lake, developed by Databricks and released in 2019, is an optimized storage layer that provides the foundation for storing data and tables in the Databricks Lakehouse Platform. However, accessing data stored in Delta Lake tables and exposing it to third-party applications through APIs can be challenging without using Spark. To address these difficulties, developers can utilize Python and FastAPI framework, a modern and efficient web framework for constructing REST APIs, to expose data stored in Delta Lake tables to third-party applications. This enables smooth and real-time consumption and interaction with the data, without any complexities.
Delta Lake Advantages
Delta Lake provides several benefits over traditional data lakes, including:
- ACID transactions: Delta Lake supports atomicity, consistency, isolation, and durability (ACID) transactions, which guarantee data integrity and consistency even in the face of concurrent access and failures.
- Schema enforcement: Delta Lake ensures that data written to the lake conforms to a specified schema, which improves data quality and makes it easier to query and analyze the data.
- Data versioning: Delta Lake allows you to version your data, so you can easily roll back to previous versions or compare different versions of the data.
- Data retention: Delta Lake provides time travel, which allows you to query data as it existed at a specific point in time. You can also set retention periods for your data, so you can automatically delete old data that is no longer needed.
- Unified batch and streaming: Delta Lake provides a unified API for batch and streaming data processing, which simplifies the development and maintenance of data pipelines.
Accessing Delta Lake Tables
When it comes to retrieving data from Delta Lake tables, there are several solutions available that allow you to connect to these tables outside of Databricks and expose them to third-party applications. Here are a few of the commonly used solutions:
- Leveraging Databricks API and API Management: Using the Databricks API, you can build your own custom APIs to interact with Delta Lake tables. By integrating Azure API Management or similar API gateway tools, you can add an additional layer of security, scalability, and manageability to the API endpoints, enabling seamless access to the data
- Utilizing third-party tools: Solutions like Athena, Azure Synapse, BigQuery, Presto, and Trino provide connectors and integration capabilities for querying and retrieving data from Delta Lake tables. These tools offer flexibility, scalability, and various query optimization features to efficiently access and process the data.
However, there is an alternative solution which is low cost, open-source, high performance, scalable, and secure is leveraging Python and FastAPI framework. By using this combination, you can benefit from Python’s extensive ecosystem, which includes libraries for data transformation, validation, and integration, making it easier to manipulate and process data retrieved from Delta Lake tables. This solution use delta-lake-reader – the lightweight wrapper for reading Delta tables without Spark.
Exposing Data With REST APIs
1. Delta Lake sample on Azure Datalake
This is a sample data of the Category table in Delta Lake format on Azure Data Lake Storage Gen 2:
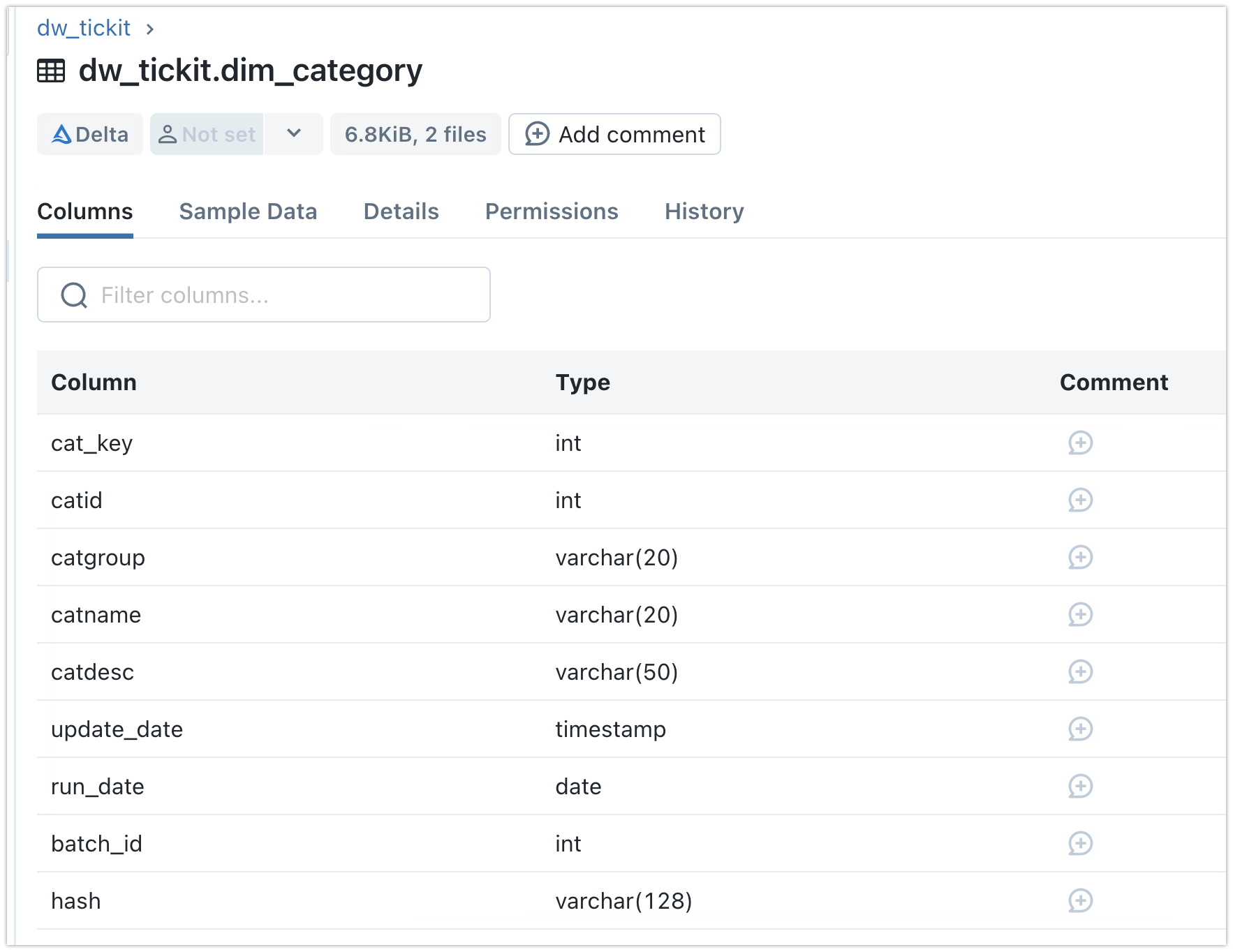
2.Delta Lake table on Databricks
The schema of the Category table in Delta Lake has been mapped from the Delta Lake folder in Databricks:
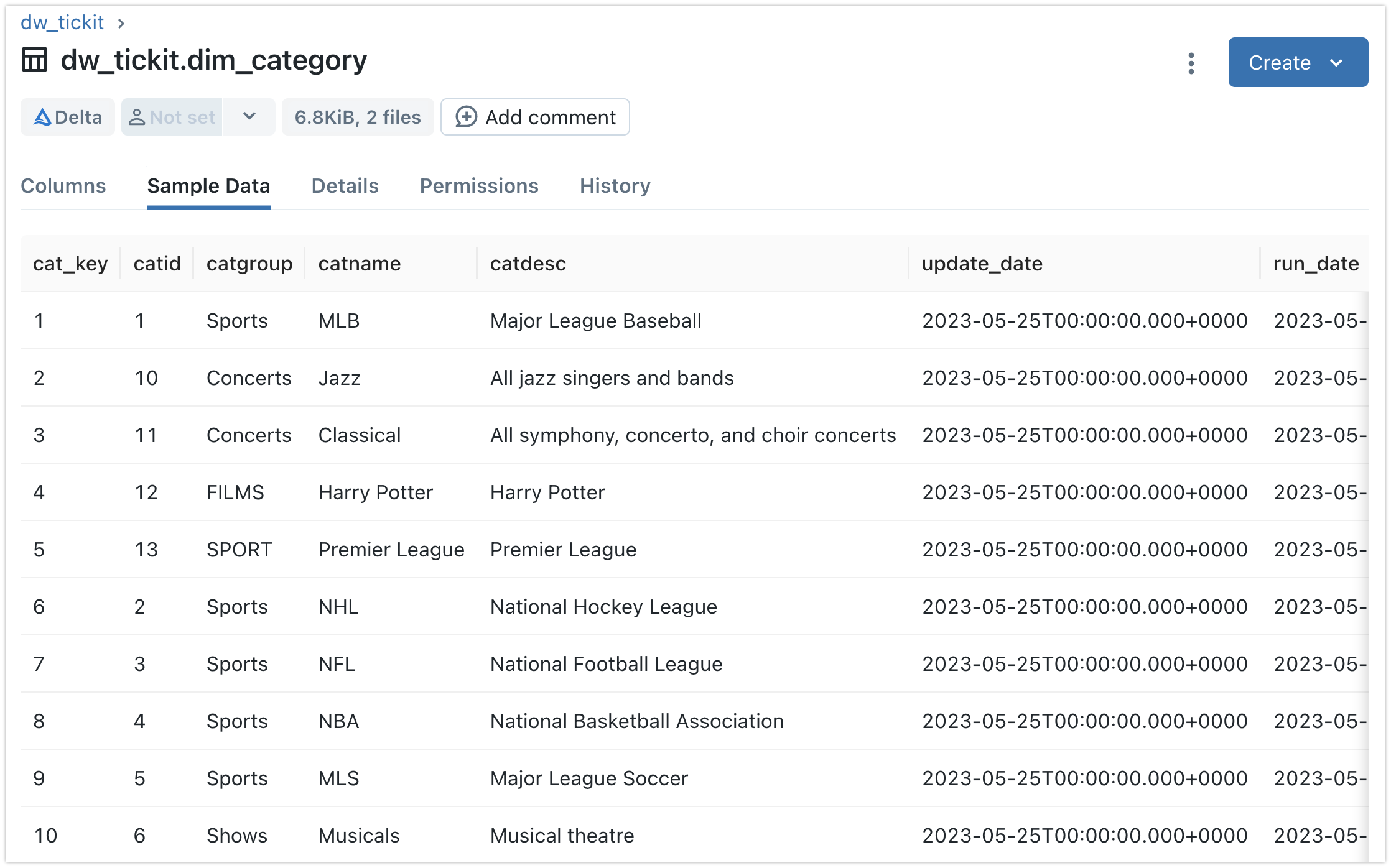
The data of Category table in Delta Lake select from Databricks:
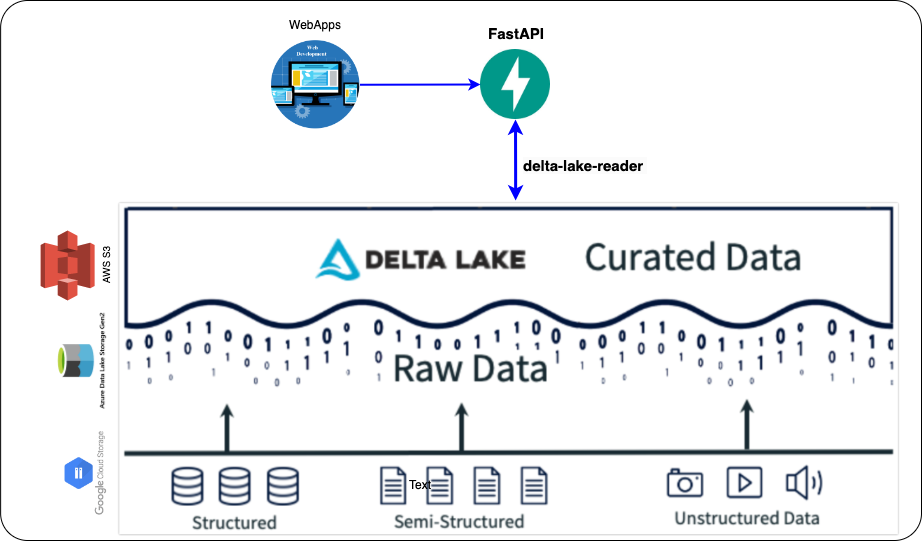
3. Connect to Delta Lake
High-level architecture of this solution:
The step by step on how to install and develop APIs to access Delta Lake:
- Install packages:
pip install "fastapi[all]"
pip install adlfs
pip3 install delta-lake-reader- Develop API using FastAPI:
Sample code for FastAPI to expose the simple API for application. In the production, refer to FastAPI document for authentication, security, etc.
from deltalake import DeltaTable from adlfs import AzureBlobFileSystem import pandas as pd @app.get("/api/getcategory") async def getcategory(): """No access token required to access this route""" fs = AzureBlobFileSystem( account_name="datalake_account_azure", credential="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" ) try: df = DeltaTable("lake/gold/category", file_system=fs).to_pandas() data_json = df.to_json() result = { "status": "success", "data": (data_json) } except Exception as ex: print(f"Excepttio:{ex}") result = { "status": "failed", "data": (ex) } return result
- API Data Request:
{"status":"success","data":"{\"cat_key\":{\"0\":-1,\"1\":1,\"2\":2,\"3\":3,\"4\":4,\"5\":5,\"6\":6,\"7\":7,\"8\":8,\"9\":9,\"10\":10,\"11\":11,\"12\":12,\"13\":13},\"catid\":{\"0\":-1,\"1\":1,\"2\":10,\"3\":11,\"4\":12,\"5\":13,\"6\":2,\"7\":3,\"8\":4,\"9\":5,\"10\":6,\"11\":7,\"12\":8,\"13\":9},\"catgroup\":{\"0\":\"unknown\",\"1\":\"Sports\",\"2\":\"Concerts\",\"3\":\"Concerts\",\"4\":\"FILMS\",\"5\":\"SPORT\",\"6\":\"Sports\",\"7\":\"Sports\",\"8\":\"Sports\",\"9\":\"Sports\",\"10\":\"Shows\",\"11\":\"Shows\",\"12\":\"Shows\",\"13\":\"Concerts\"},\"catname\":{\"0\":\"unknown\",\"1\":\"MLB\",\"2\":\"Jazz\",\"3\":\"Classical\",\"4\":\"Harry Potter\",\"5\":\"Premier League\",\"6\":\"NHL\",\"7\":\"NFL\",\"8\":\"NBA\",\"9\":\"MLS\",\"10\":\"Musicals\",\"11\":\"Plays\",\"12\":\"Opera\",\"13\":\"Pop\"},\"catdesc\":{\"0\":\"unknown\",\"1\":\"Major League Baseball\",\"2\":\"All jazz singers and bands\",\"3\":\"All symphony, concerto, and choir concerts\",\"4\":\"Harry Potter\",\"5\":\"Premier League\",\"6\":\"National Hockey League\",\"7\":\"National Football League\",\"8\":\"National Basketball Association\",\"9\":\"Major League Soccer\",\"10\":\"Musical theatre\",\"11\":\"All non-musical theatre\",\"12\":\"All opera and light opera\",\"13\":\"All rock and pop music concerts\"},\"update_date\":{\"0\":0,\"1\":1683763200000,\"2\":1683763200000,\"3\":1683763200000,\"4\":1683763200000,\"5\":1683763200000,\"6\":1683763200000,\"7\":1683763200000,\"8\":1683763200000,\"9\":1683763200000,\"10\":1683763200000,\"11\":1683763200000,\"12\":1683763200000,\"13\":1683763200000},\"run_date\":{\"0\":0,\"1\":1683763200000,\"2\":1683763200000,\"3\":1683763200000,\"4\":1683763200000,\"5\":1683763200000,\"6\":1683763200000,\"7\":1683763200000,\"8\":1683763200000,\"9\":1683763200000,\"10\":1683763200000,\"11\":1683763200000,\"12\":1683763200000,\"13\":1683763200000},\"batch_id\":{\"0\":0,\"1\":277,\"2\":277,\"3\":277,\"4\":277,\"5\":277,\"6\":277,\"7\":277,\"8\":277,\"9\":277,\"10\":277,\"11\":277,\"12\":277,\"13\":277},\"hash\":{\"0\":null,\"1\":\"f09fe6199bed3a4392707993335930b169ed02ffbfee6348ae094a9473488dfa\",\"2\":\"8b14858c4df400eca29cba1b444c85ba380176ceb88dc498f6703f2d761b9830\",\"3\":\"dfe572c7b2936e94fe2744f95816e8fd5bd9ae51ce3ce10d2a4272d403322506\",\"4\":\"723e3f4d5b866a4963165c428534836ce3ce3c874f38e312aa2740d469887439\",\"5\":\"3c5273fa027b953f86e6fc9836f061xaff6596b7141eae714bbce612b7bec363e\",\"6\":\"4425fdaccb7ec3698cedf4115812ecb9c265d0d62597628fca3219a32ca0697f\",\"7\":\"3f8f8256a74cde0605bf6082818c2b7bf56c9f6d2f35f36c7fd52e7473249eb7\",\"8\":\"62455b22140dc43457ae444a1ddd19b629132220ed13894fe9d9abb858a2f61f\",\"9\":\"4833dfd72fadb64a870f2430e2b908f53bf88e7a1b4d88fb6602e6a6d913d49a\",\"10\":\"b21ca2f65ecd0d4e3b102fe6cfa996890194db0832e9811f060519e89911c5b7\",\"11\":\"0fb62bac736aae191015d9b5f262b841b75ea9ee6e59f8c88af669c07cde575f\",\"12\":\"7400e00c9768d4c1fa6628181c99302caf5992da72b94f2ead821b377f0f4178\",\"13\":\"84ff7dc87509731ff46073bd0c5ac07ee170ca520701b7dc0537bd415e80dd4e\"}}"}Best Practices
By following these best practices, you can ensure that your REST API for exposing Delta Lake tables is secure, efficient, and user-friendly:
- Design a consistent and intuitive API schema: Create a well-structured API schema following RESTful principles. Use meaningful resource names, standard HTTP methods (GET, POST, PUT, DELETE), and consistent request/response formats. This ensures clarity and ease of use for API consumers.
- Implement secure authentication and authorization: Protect your REST API by implementing robust authentication and authorization mechanisms. Utilize industry-standard protocols like OAuth or API keys to authenticate users and define granular access control policies to secure access to Delta Lake tables based on user roles and permissions.
- Optimize performance with caching and pagination: Improve performance by implementing caching mechanisms to reduce the load on Delta Lake tables. Utilize HTTP caching headers or in-memory caching to store frequently accessed data. Implement pagination to efficiently handle large result sets and avoid overwhelming clients with excessive data.
- Handle errors gracefully: Implement comprehensive error handling to provide informative and meaningful error responses. Use appropriate HTTP status codes and include detailed error messages to guide API consumers in troubleshooting and resolving issues.
- Thoroughly document your API: Provide thorough documentation that explains the purpose, functionality, and usage of each API endpoint. Include details on request/response formats, authentication requirements, query parameters, and error handling. Clear documentation helps developers understand and integrate with your API effectively.
Conclusion
- By combining Delta Lake tables with FastAPI and Python’s extensive ecosystem, developers can efficiently build scalable and data-driven applications with streamlined API access and manipulation. This solution is suitable for those who want quick access to Delta Lake without the need to build an entire environment like Spark, AI or when dealing with not excessively large datasets.
In the next article, I will describe how to use FastAPI to connect directly to Databricks to leverage the benefits of Databricks for big data processing. Please read this article “Using FastAPI Connect To Databricks“.