



Key takeaways:
By employing FastAPI to establish a connection with Databricks, users can effortlessly access Delta Lake tables and make them accessible through APIs. This integration facilitates real-time data consumption and interaction, empowering developers to build efficient and scalable applications that leverage the capabilities of Databricks for Big Data processing and Delta Lake.
Introduction
FastAPI serves as a powerful framework for API backends, allowing connections to Databricks, a robust analytics and data processing platform. This integration allows for seamless access to Delta Lake tables, leveraging Databricks’ advanced capabilities for data management and analysis. By combining FastAPI’s streamlined API development with Databricks’ extensive features, developers can harness the full potential of Databricks, enabling scalable, efficient, and data-driven applications.
Advantages of Databricks
Databricks, a leading Lakehouse platform built on Apache Spark, offers numerous benefits in the world of data, analytics, and AI.
- Unified Platform: Databricks unifies data, analytics, and AI on a single platform, simplifying workflows and enabling seamless collaboration.
- Built-in Libraries: With built-in libraries for data processing and machine learning, Databricks provides a comprehensive toolkit for data scientists and engineers.
- Scalability: Databricks offers a scalable infrastructure that can handle large volumes of data and accommodate growing workloads. It leverages cloud-based resources to scale up or down based on demand, ensuring optimal performance and cost-effectiveness.
- Streamlined Data Management: Databricks offers automated and reliable ETL processes, fast data ingestion, and open and secure data sharing, ensuring efficient data management and enabling faster insights and decision-making.
- Databricks promotes the concept of a “lakehouse” architecture, which combines the best features of data lakes and data warehouses. It allows for efficient storage, management, and analysis of structured and unstructured data, offering the benefits of both worlds.
High level architecture
The following diagram outline the architecture to establish a direct connection between FastAPI and the Delta Lake table through Databricks and exposes data through APIs.
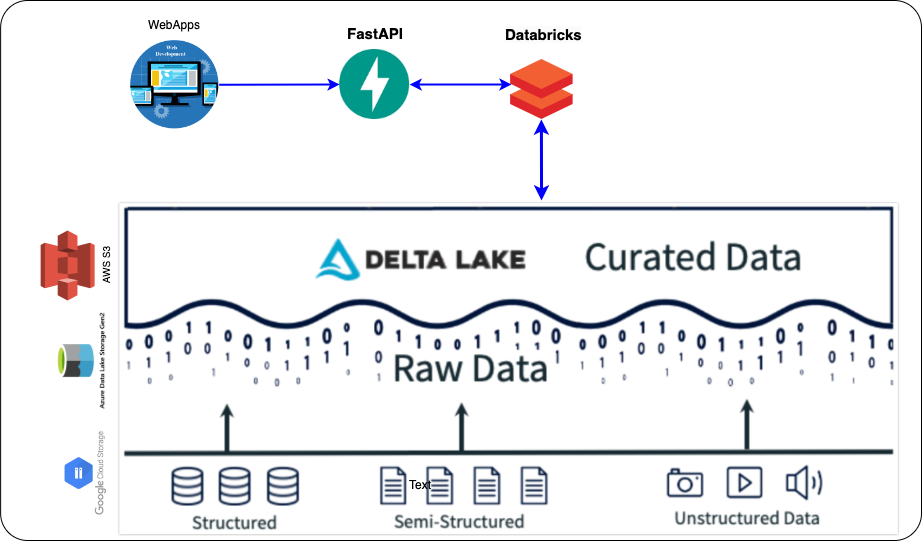
The sample presented here uses the data(dim_category) from the previous post as a demonstration.
Steps to set up APIs to access Databricks
Environment Setup
- Python >=3.9
- python packages:
- fastapi
- pydantic
- SQLAlchemy
- sqlalchemy-databricks
- File “.env” to store environment variables configure to connect Databricks (or use Key Vault to store these values for more security). Get this value in “Advanced Options” of the cluster compute and generate the PAS for ACCESS_TOKEN in “User Setting”:
- SERVER_HOSTNAME=adb-xxxxxxxxxx.azuredatabricks.net
- HTTP_PATH=sql/protocolv1/o/xxxxxxx/xxxx-xxxxxx-xxxxxxxx
- ACCESS_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxx
- File config.py to read variables and file main.py to run the FastAPI.
Read config variables
This sample read Databricks configuration from environment variables using Python:
from typing import Optional, Dict, Any from pydantic import BaseSettings, validator class Settings(BaseSettings): SERVER_HOSTNAME: str HTTP_PATH: str ACCESS_TOKEN: str DATABRICKS_DB: str = "dw_tickit" DATABRICKS_DATABASE_URI: Optional[str] = None @validator("DATABRICKS_DATABASE_URI", pre=True) def assemble_db_connection(cls, v: Optional[str], values: Dict[str, Any]) -> Any: if isinstance(v, str): return v return "databricks+connector://token:{}@{}:443/{}".format( values.get("ACCESS_TOKEN"), values.get("SERVER_HOSTNAME"), values.get("DATABRICKS_DB"), ) class Config: case_sensitive = True env_file = ".env" settings = Settings()
Expose API via FastAPI
Steps to create APIs doing the following actions on dim_category table:
- Create a new category (
POST) - Read a category by a specific catid (
GET) - Update an existing category (
PUT) - Delete a category (
DELETE)
The code below is the whole setup for all the routes in the fastapi_databricks.py file for the API. Here’s the code:
# How to run: # uvicorn fastapi_databricks:app --reload from fastapi import FastAPI, Depends, Query, status from fastapi.responses import JSONResponse from fastapi.encoders import jsonable_encoder from sqlalchemy import create_engine, Column, Integer, String, DateTime, Date from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base from pydantic import BaseModel from random import randrange from config import settings app = FastAPI() engine = create_engine( settings.DATABRICKS_DATABASE_URI, connect_args={ "http_path": settings.HTTP_PATH, }, ) Session = sessionmaker(autocommit=False, autoflush=False, bind=engine) def session(): db = Session() try: yield db finally: db.close() Base = declarative_base(bind=engine) # Entity category class Category(Base): __tablename__ = "dim_category" cat_key = Column(Integer, primary_key=True, nullable=False) catid = Column(Integer, nullable=False) catgroup = Column(String, nullable=True) catname = Column(String, nullable=True) catdesc = Column(String, nullable=True) update_date = Column(DateTime, nullable=True) run_date = Column(Date, nullable=True) batch_id = Column(Integer, nullable=True) hash = Column(String, nullable=True) # Request Body class CategoryRequest(BaseModel): catname: str = Query(..., max_length=50) catgroup: str = Query(..., max_length=50) @app.get("/") def root(): return {"message": "Hi Databricks!"} @app.get("/category") def get_category( catid: int = None, catname: str = Query(None, max_length=50), db: Session = Depends(session), ): if catid is not None: result_set = db.query(Category).filter(Category.catid == catid).all() elif catname is not None: result_set = db.query(Category).filter(Category.catname == catname).all() else: result_set = db.query(Category).all() response_body = jsonable_encoder(result_set) return JSONResponse(status_code=status.HTTP_200_OK, content=response_body) @app.post("/category") def create_category(request: CategoryRequest, db: Session = Depends(session)): category = Category( cat_key=randrange(1_000_000, 10_000_000), catid=randrange(1_000_000, 10_000_000), catname=request.catname, catgroup=request.catname, ) db.add(category) db.commit() response_body = jsonable_encoder({"category_id": category.catid}) return JSONResponse(status_code=status.HTTP_200_OK, content=response_body) @app.put("/category/{id}") def update_category(catid: int, request: CategoryRequest, db: Session = Depends(session)): category = db.query(Category).filter(Category.catid == catid).first() if category is None: return JSONResponse(status_code=status.HTTP_404_NOT_FOUND) category.catname = request.catname category.catgroup = request.catgroup db.commit() response_body = jsonable_encoder({"category_id": category.catid}) return JSONResponse(status_code=status.HTTP_200_OK, content=response_body) @app.delete("/category/{id}") def delete_category(catid: int, db: Session = Depends(session)): db.query(Category).filter(Category.catid == catid).delete() db.commit() response_body = jsonable_encoder({"category_id": catid, "msg": "record deleted"}) return JSONResponse(status_code=status.HTTP_200_OK, content=response_body)
The result example when call the API to get all the categories http://127.0.0.1:8000/category:
[{"cat_key":1,"catdesc":"Major League Baseball","catname":"MLB","run_date":"2023-05-25","hash":"f09fe6199bed3a4392707993335930b169ed02ffbfee6348ae094a9473488dfa","catid":1,"catgroup":"Sports","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":2,"catdesc":"All jazz singers and bands","catname":"Jazz","run_date":"2023-05-25","hash":"8b14858c4df400eca29cba1b444c85ba380176ceb88dc498f6703f2d761b9830","catid":10,"catgroup":"Concerts","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":3,"catdesc":"All symphony, concerto, and choir concerts","catname":"Classical","run_date":"2023-05-25","hash":"dfe572c7b2936e94fe2744f95816e8fd5bd9ae51ce3ce10d2a4272d403322506","catid":11,"catgroup":"Concerts","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":4,"catdesc":"Harry Potter","catname":"Harry Potter","run_date":"2023-05-25","hash":"723e3f4d5b866a4963165c428534836ce3ce3c874f38e312aa2740d469887439","catid":12,"catgroup":"FILMS","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":5,"catdesc":"Premier League","catname":"Premier League","run_date":"2023-05-25","hash":"3c5273fa027b953f86e6fc9836f061aff6596b7141eae714bbce612b7bec363e","catid":13,"catgroup":"SPORT","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":6,"catdesc":"National Hockey League","catname":"NHL","run_date":"2023-05-25","hash":"4425fdaccb7ec3698cedf4115812ecb9c265d0d62597628fca3219a32ca0697f","catid":2,"catgroup":"Sports","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":7,"catdesc":"National Football League","catname":"NFL","run_date":"2023-05-25","hash":"3f8f8256a74cde0605bf6082818c2b7bf56c9f6d2f35f36c7fd52e7473249eb7","catid":3,"catgroup":"Sports","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":8,"catdesc":"National Basketball Association","catname":"NBA","run_date":"2023-05-25","hash":"62455b22140dc43457ae444a1ddd19b629132220ed13894fe9d9abb858a2f61f","catid":4,"catgroup":"Sports","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":9,"catdesc":"Major League Soccer","catname":"MLS","run_date":"2023-05-25","hash":"4833dfd72fadb64a870f2430e2b908f53bf88e7a1b4d88fb6602e6a6d913d49a","catid":5,"catgroup":"Sports","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":10,"catdesc":"Musical theatre","catname":"Musicals","run_date":"2023-05-25","hash":"b21ca2f65ecd0d4e3b102fe6cfa996890194db0832e9811f060519e89911c5b7","catid":6,"catgroup":"Shows","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":11,"catdesc":"All non-musical theatre","catname":"Plays","run_date":"2023-05-25","hash":"0fb62bac736aae191015d9b5f262b841b75ea9ee6e59f8c88af669c07cde575f","catid":7,"catgroup":"Shows","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":12,"catdesc":"All opera and light opera","catname":"Opera","run_date":"2023-05-25","hash":"7400e00c9768d4c1fa6628181c99302caf5992da72b94f2ead821b377f0f4178","catid":8,"catgroup":"Shows","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":13,"catdesc":"All rock and pop music concerts","catname":"Pop","run_date":"2023-05-25","hash":"84ff7dc87509731ff46073bd0c5ac07ee170ca520701b7dc0537bd415e80dd4e","catid":9,"catgroup":"Concerts","update_date":"2023-05-25T00:00:00+00:00","batch_id":279},{"cat_key":-1,"catdesc":"unknown","catname":"unknown","run_date":"1970-01-01","hash":null,"catid":-1,"catgroup":"unknown","update_date":"1970-01-01T00:00:00+00:00","batch_id":0}]
Notes
– Be aware of the data size and the cost to query the data
– Be mindful of cluster costs
Summary
With this setup, you can quickly create a full CRUD API that leverages data from the Lakehouse architecture on Databricks and provide ability to process data real-time. This baseline example can also open up more API possibilities with integrations into ML models deployed in Databricks.
1 thought on “Databricks – Connecting to Databricks via FASTAPI”
Pingback: Databricks Lakehouse is a Must-Have Investment for Business Success
Comments are closed.